神经网络和深度学习[1-2]
神经网络和深度学习[1-3]
神经网络和深度学习[1-4]
改善深层神经网络:超参数调试、正则化以及优化【2-1】
改善深层神经网络:超参数调试、正则化以及优化【2-2】
改善深层神经网络:超参数调试、正则化以及优化【2-3】
结构化机器学习项目 3
Ng的深度学习视频笔记,长期更新
2.2 经典网络
这一部分主要讲解了三个卷积网络模型
LeNet-5模型如下图所示: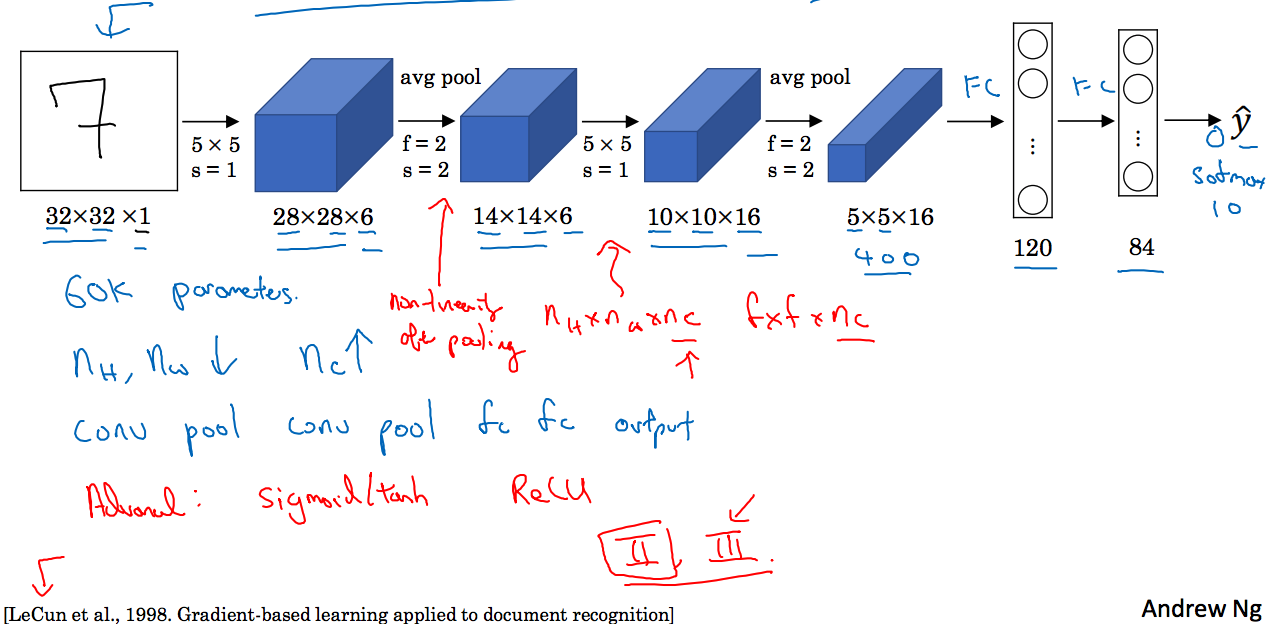
这里输入为32x32x1的矩阵,经过6个5x5的过滤器,步长为1的卷积层后得到28x28x6矩阵,然后经过池化层,这里使用平均池化,得到14x14x6的矩阵,。。。。
可以看到矩阵的长宽在不断缩小,通道数在不断增大。
AlexNet模型如下图所示: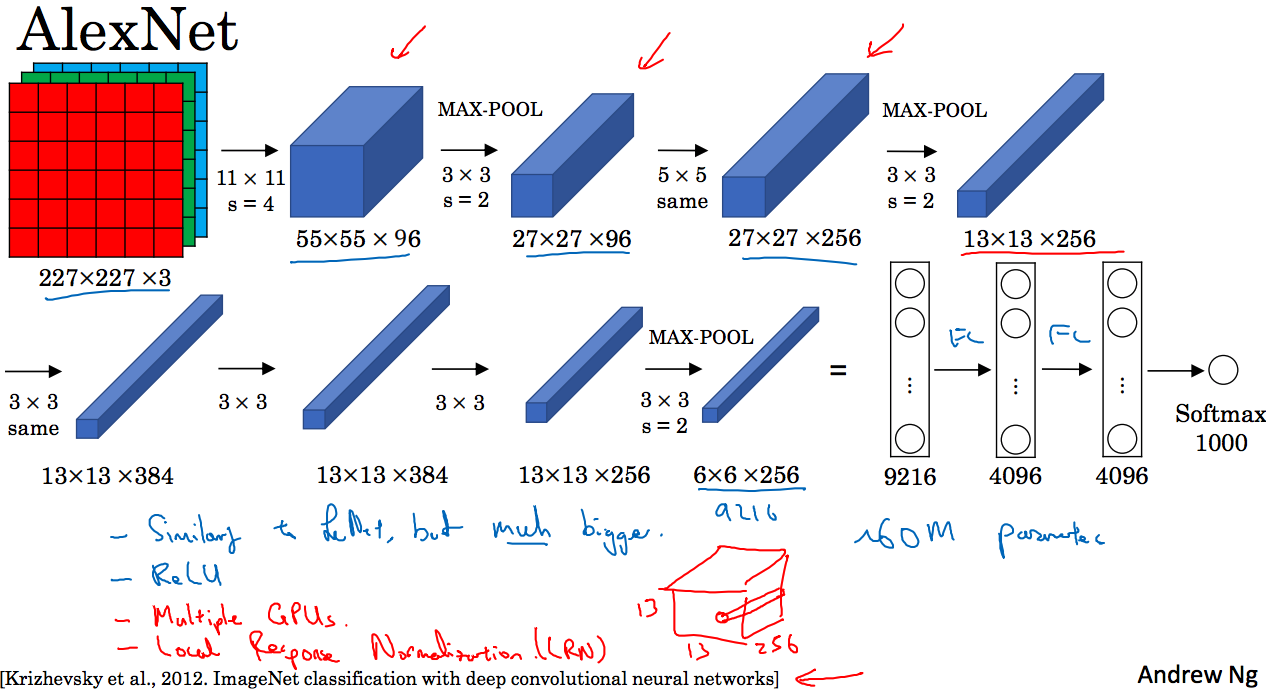
输入为227x227x3的矩阵,经过过滤器为11x11,步长为4的卷积层得到55x55x96的矩阵,然后通过过滤器为3x3,步长为2的池化层得到27x27x96的矩阵,继续童谣的过程,最后得到6x6x256的矩阵,展开为9216个特征值作为全连接层的输入…
VGG-16模型如下图所示: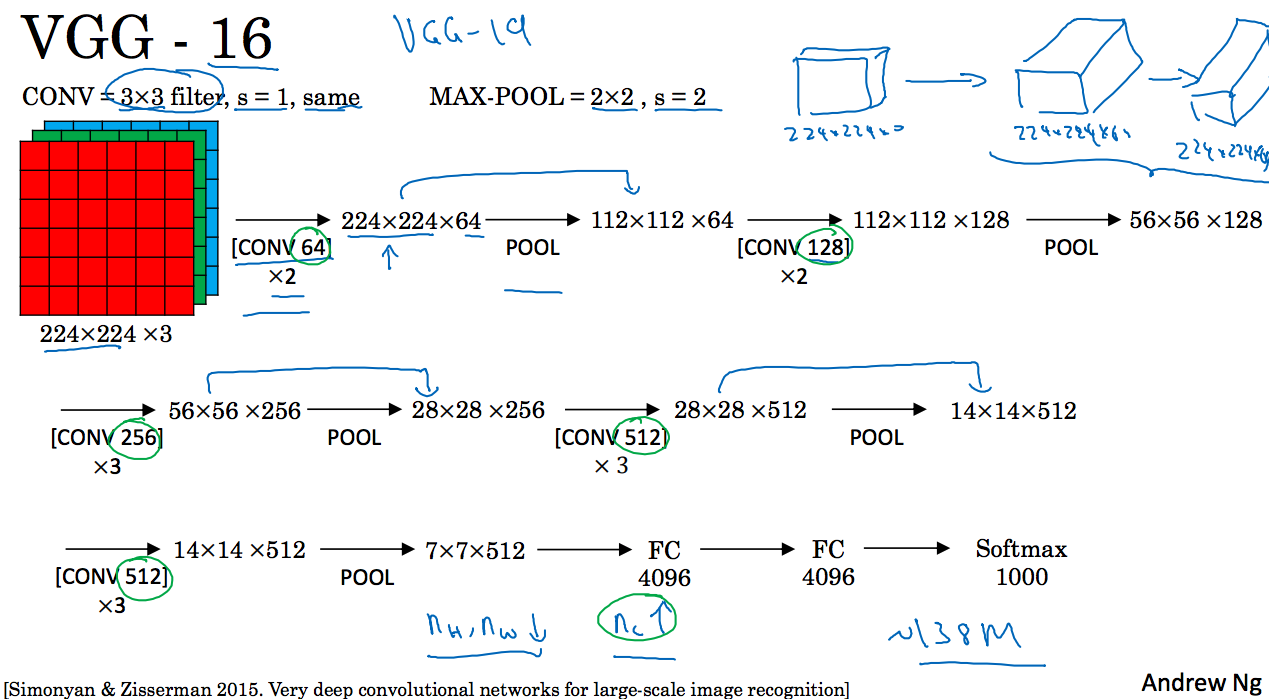
输入为224x224x3的矩阵,经过过滤器大小为3x3,个数为64,步长为1,padding=1的卷积层2次,这里same的意思是说卷积前后矩阵的长宽不变。继续经过池化层将矩阵的大小减半。。。
2.3 残差网络
非常深得网络很难训练,因为存在梯度消失和梯度爆炸问题。这里学习跳远连接,可以从某一网络获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层,可以利用跳远连接构建能够训练深度网络的ResNets。
ResNets是由残差模块构建的,那么什么是残差块呢?如下图所示: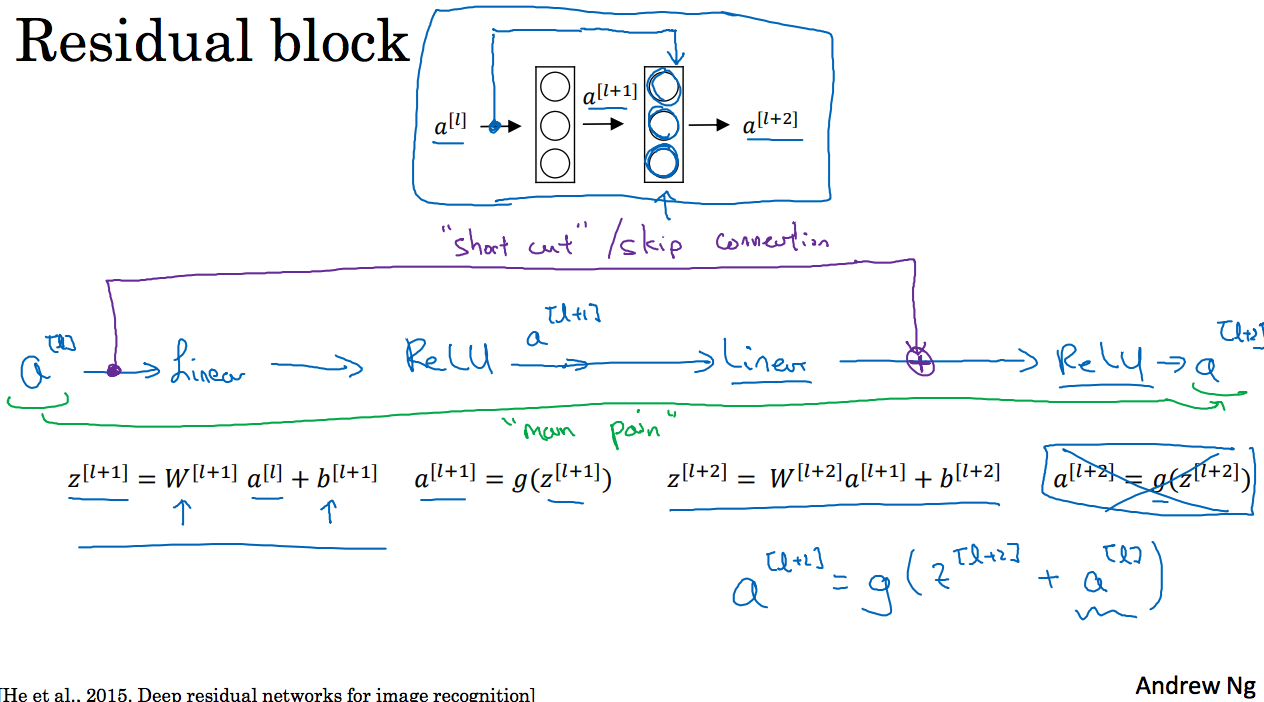
这里是神经网络的一部分,我们将传递给后二层的激活函数前,这里就有
这里加上后对结果的影响就是残差块,也就是产生了残差块,【这里我不知道为什么这样做】
如下图所示,残差网络每隔一个做一次跳远连接,一共5个残差模块: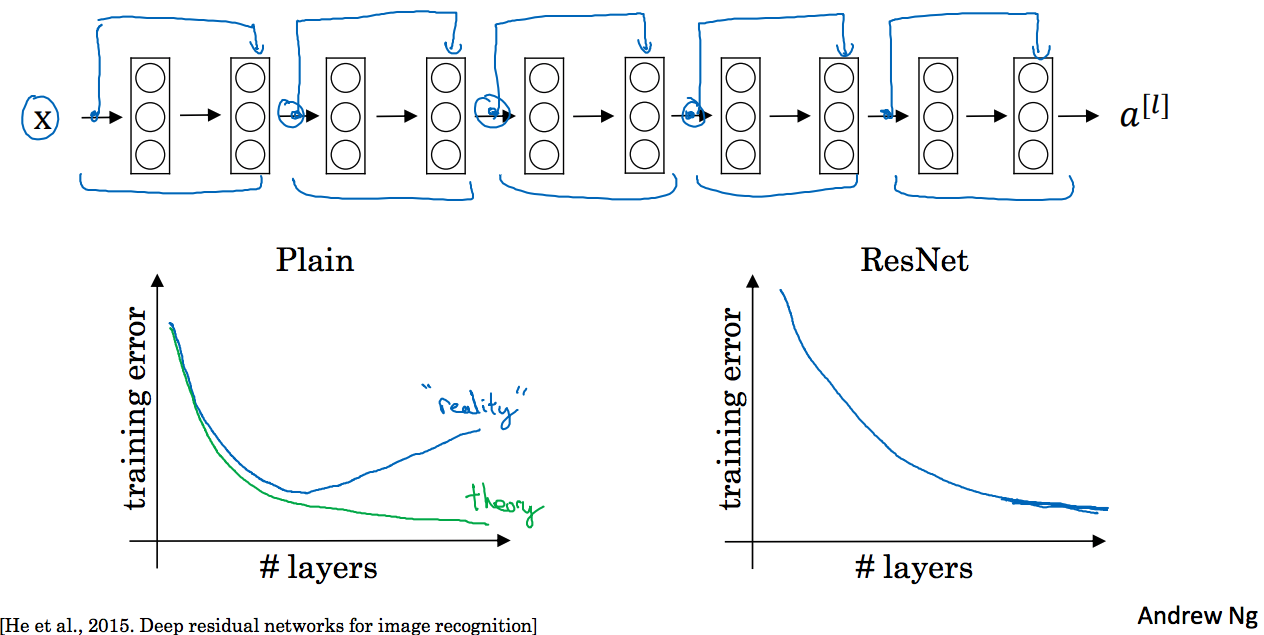
这里左边图显示一般的网络随着层数的增加,训练误差有一个最小值,但是ResNet网络却没有最小值。
2.4 残差网络为什么有用?
一个网络深度越深,它在训练集上训练网络的效率会有所减弱,这也是有时候我们不希望加深网络的原因,但是对于训练ResNet而言并不是这样的。举个例子,如下图所示: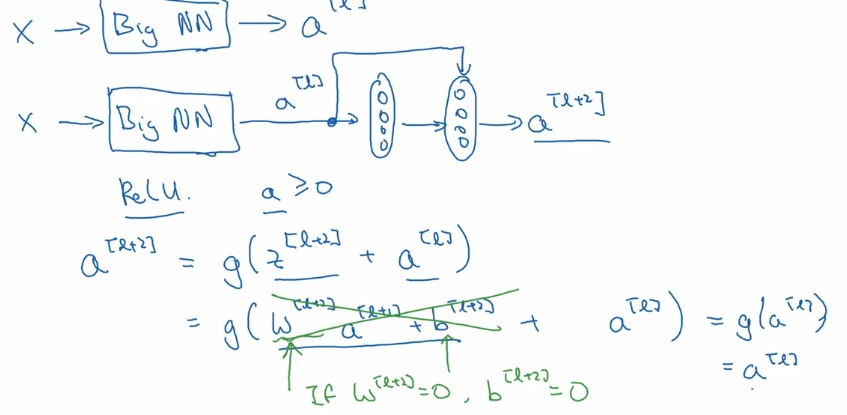
直接看最后一个式子,我们可以看到如果更新的时候那么,也就是中间两层的结果是一个等价转换,这意味着即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为这个恒等式学习起来很简单。
残差网络的起作用的主要原因在于这些残差网络学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络效率。
这里我们一般构建的残差模块的输入和输出具有相同的维度,比如和,但是如果输入和输出不是同一维度的话,我们就需要再增加一个矩阵,比如:
这里的维度是256,的维度是128,那么需要添加一个矩阵,它的维度是256x128.
2.5 网络中的网络以及1x1卷积
这一节很简单,就讲了一下1x1卷积以及其作用,其中的一个作用就是,比如你想将28x28x192的矩阵的通道变小,而不改变长宽,变为28x28x32,那么虽然可以使用步长和padding解决,但是使用1x1的过滤矩阵则更合适,使用32个1x1x192的矩阵。
2.6 谷歌Inception网络介绍
Inception网络的作用是代替你选择什么样的过滤器,或者确定是否需要创建卷积层或池化层,如下图所示,我们使用不同的过滤器以及池化层,得到一个28x28x256的矩阵: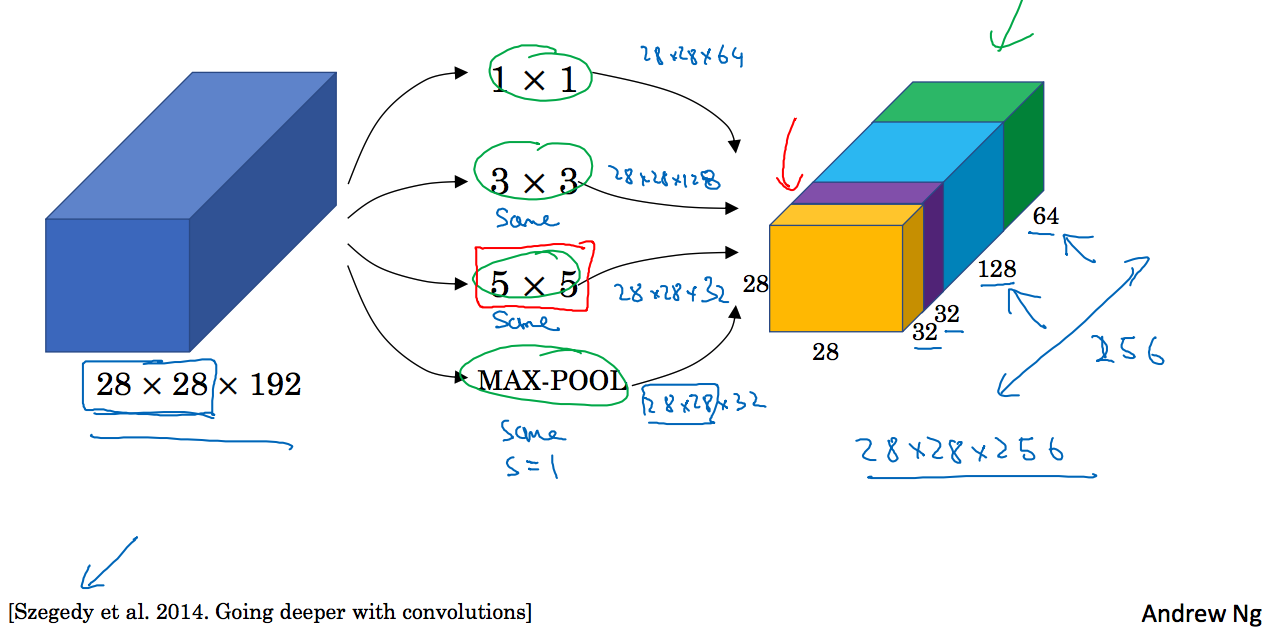
这就是Inception网络的核心思想。
观察上图中5x5的过滤器,将28x28x192的矩阵卷积后变为28x28x32,其计算成本为:
我们可以通过找到一个最小的瓶颈矩阵来减小这一过程的计算量,这也是1x1过滤器的应用,如下图所示: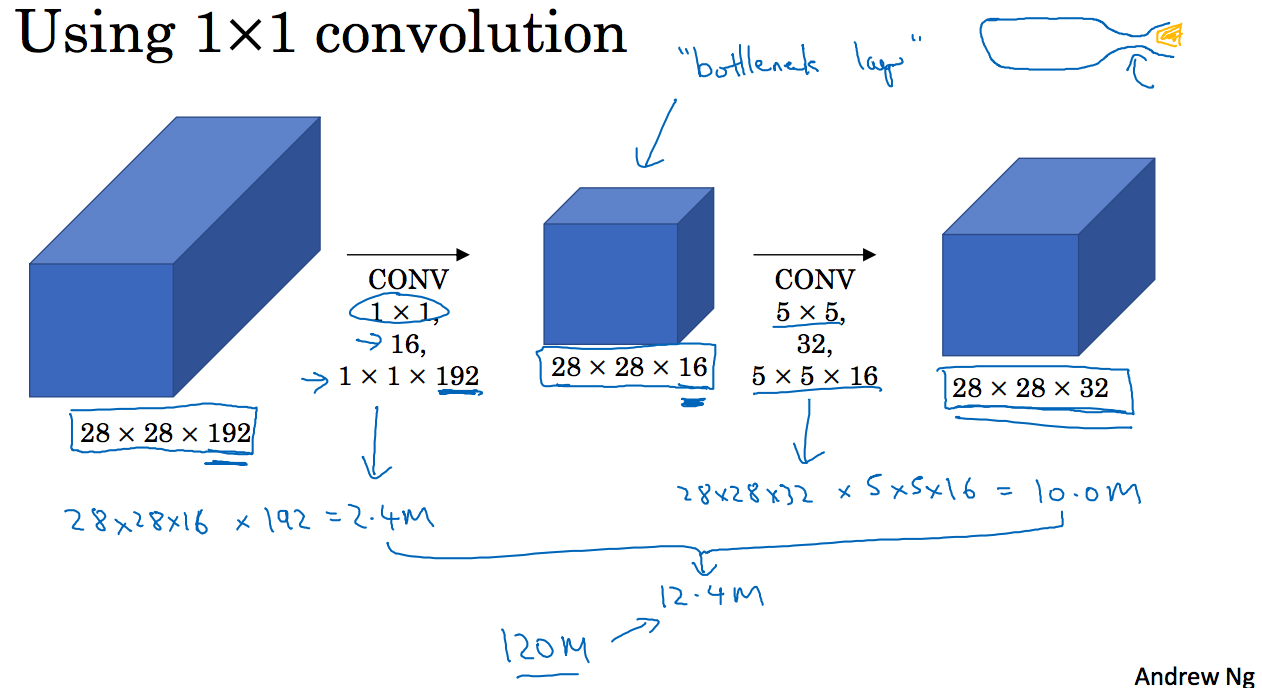
其计算成本:
实践证明,一定存在一个瓶颈矩阵满足上面的转化过程。
2.7 Inception 网络
如下图所示,以28x28x192的矩阵作为输入,输出一个28x28x256的矩阵: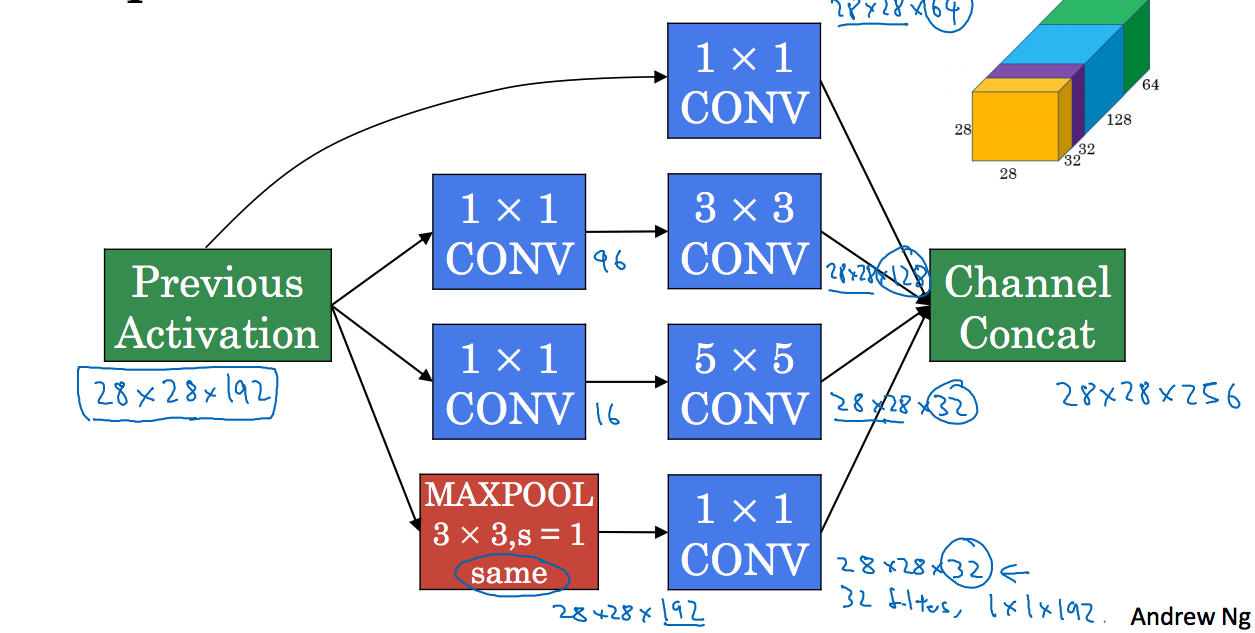
这里和之前提到的不一样,使用了1x1的过滤器来减小计算量,最下面的池化层池化后的结果仍然是28x28x192得矩阵,需要通过1x1的过滤器来将通道缩小。
下面这张图取自Szegety et al.的论文: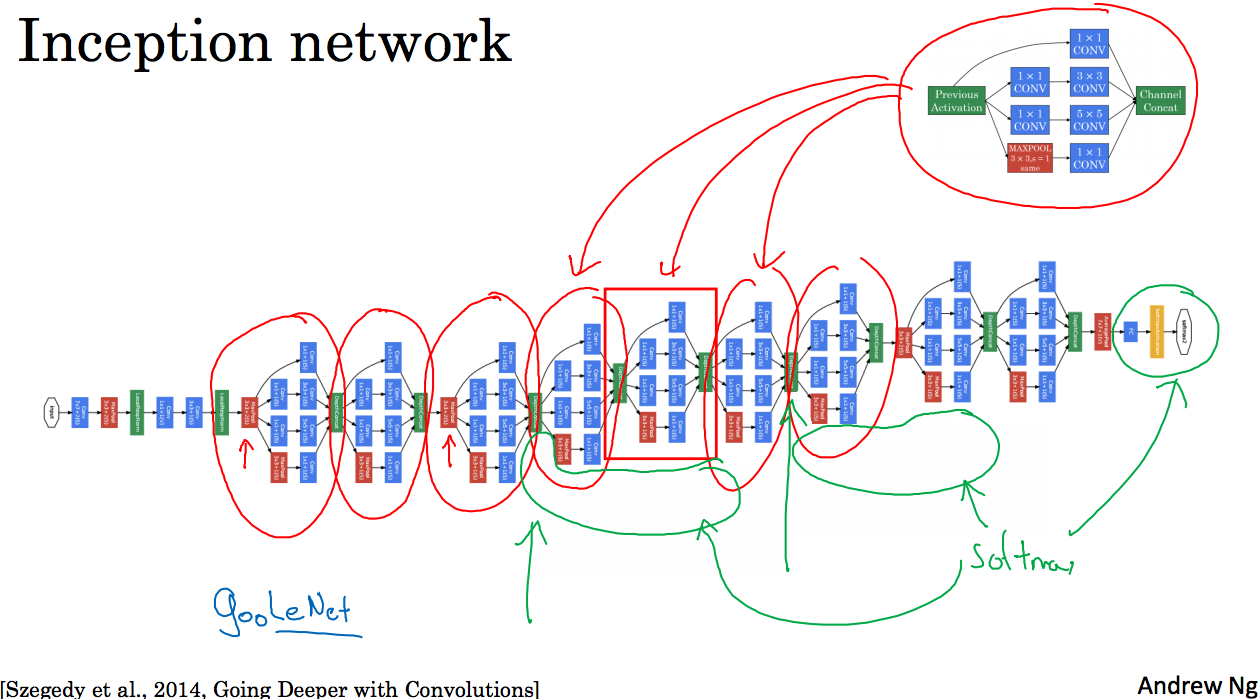
可以看到有很多的重复单元,其中还有一部分影藏层,上面没有显示,是在画绿色圈内,每一层都会经过全连接层,Softmax函数,然后输出,做出预测,最后将这些预测综合,这样做防止网络过拟合。
后面的就不记录了,很多东西好像不是很适合现在学习…

