神经网络和深度学习[1-2]
神经网络和深度学习[1-3]
神经网络和深度学习[1-4]
改善深层神经网络:超参数调试、正则化以及优化【2-1】
改善深层神经网络:超参数调试、正则化以及优化【2-2】
改善深层神经网络:超参数调试、正则化以及优化【2-3】
结构化机器学习项目 3
Ng的深度学习视频笔记,长期更新
4.1 Deep L-layer Neural network
如下图所示,一个4层的神经网络,给出一些符号约定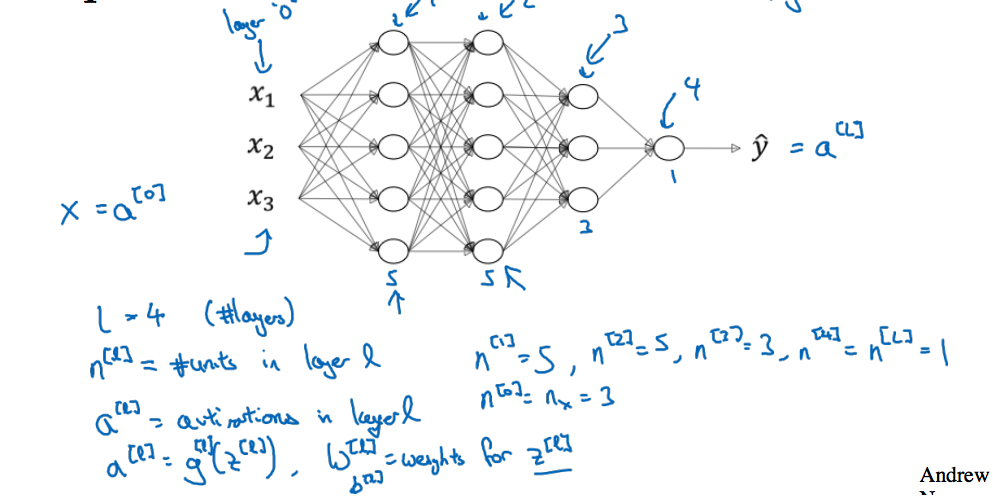
4.2 Forward Propagation in a Deep Network
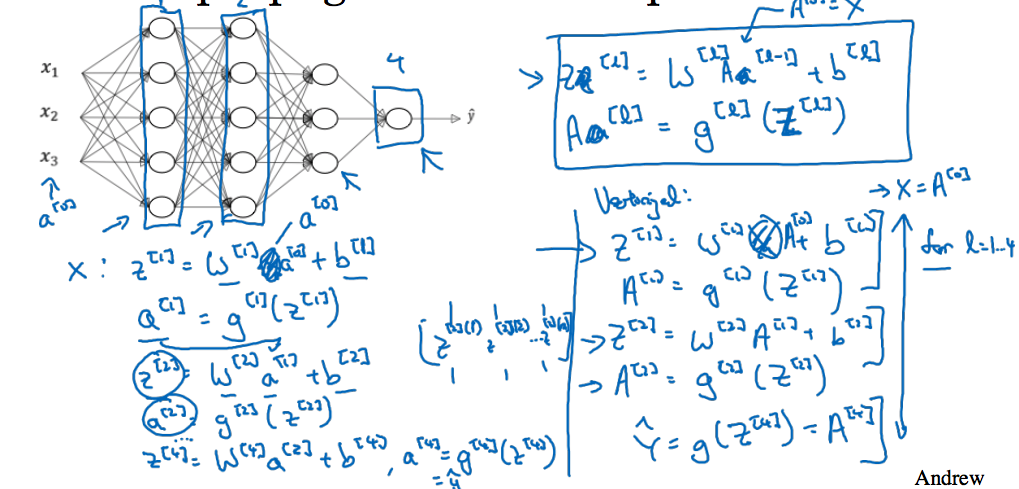
对于每一层的Z和A有如下公式:
4.3 Getting your matrix dimensions right
讲到了对于一个深层神经网络中各层参数及输出的维度,这里我之间有做过,就不罗列了
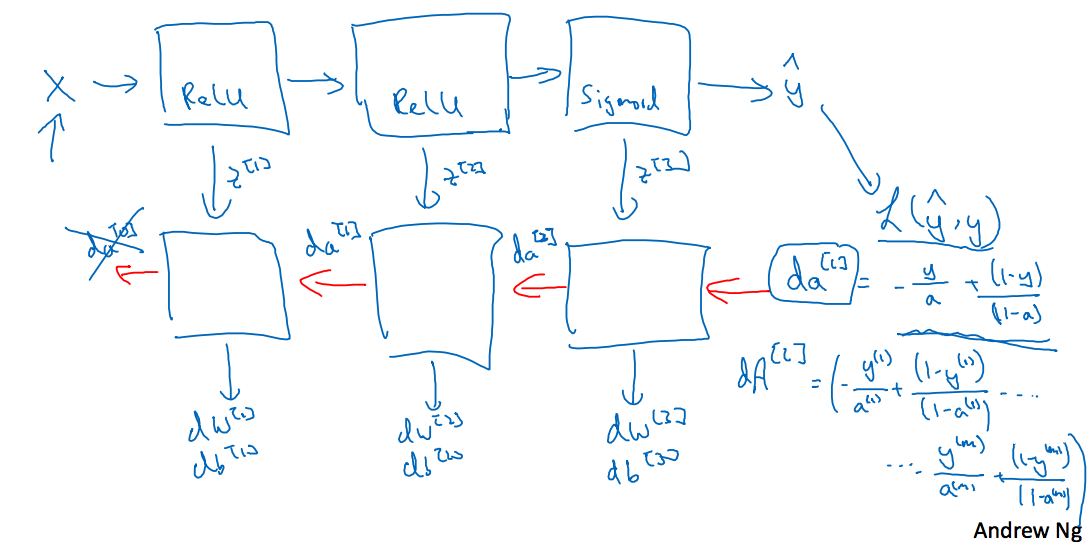
4.5 Building blocks of deep neural networks
继续上图,给出的是某一层的前向和反向的分析,在前向传播的过程中,传入,输出,这个过程需要计算出,才能得到,而在反向传播中需要,因此需要将存储下来,供反向传播使用;反向传播是一个相反的过程,传入,输出,并计算;这里为什么需要呢,因为求时,需要求解,而求解又要求解,如果激活函数是函数的话,该结果就是,这里就要用到,避免重复计算。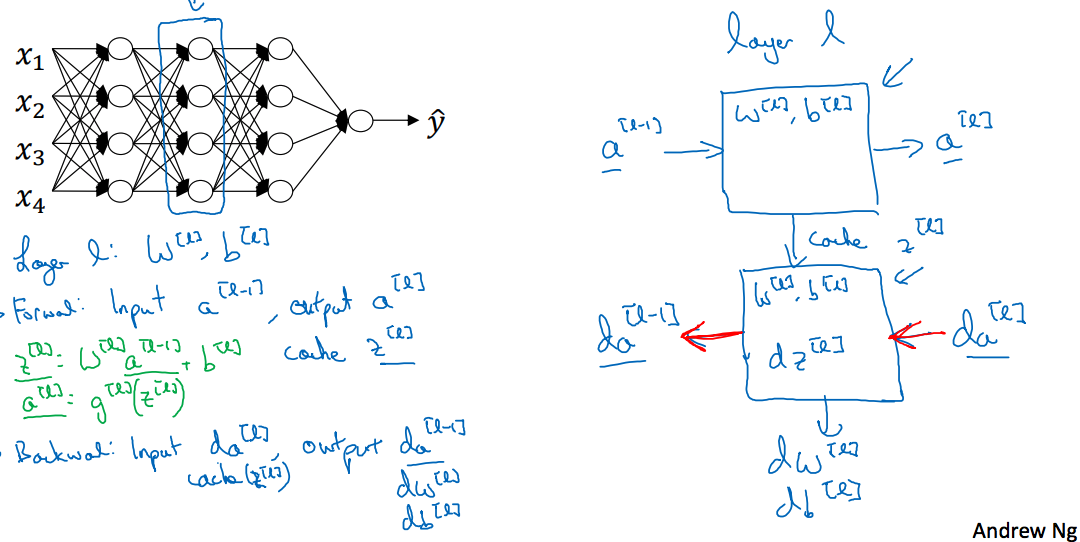
下面这个是完整的神经网络过程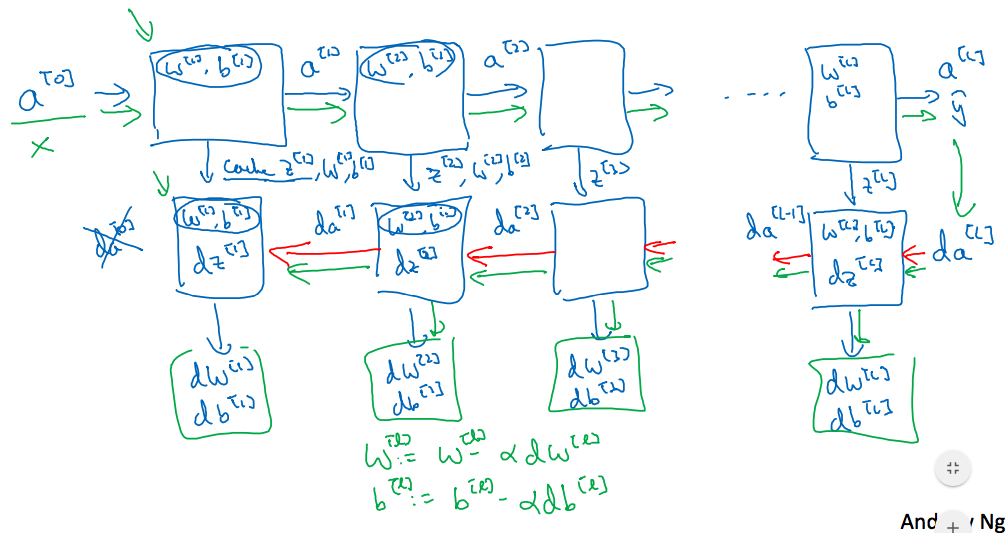
4.6 Forward and backward propagation
这节在讲上面的算法如何用向量表示及用代码实现,先上两张图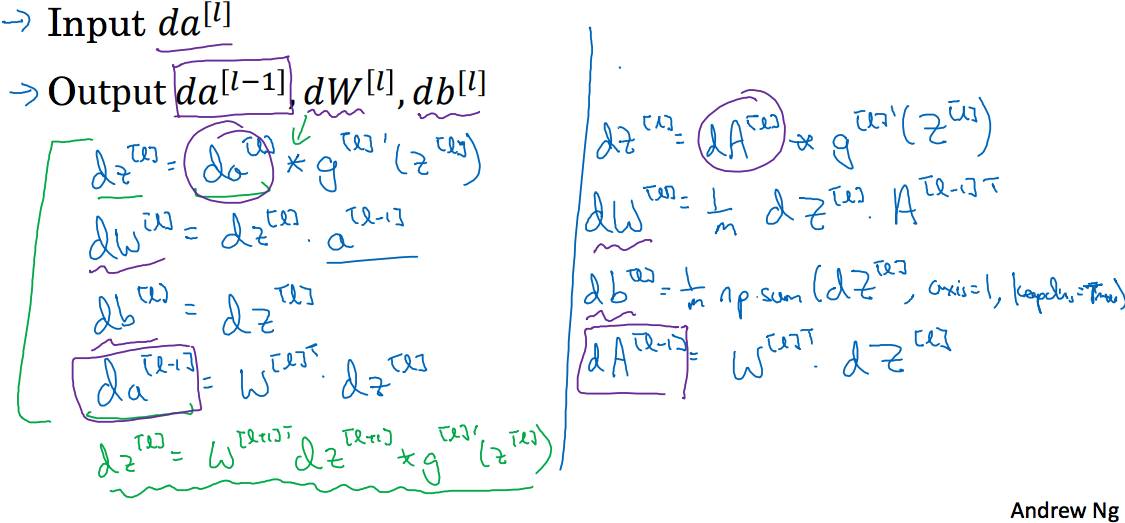
上面第一张图中有4组公式,也是我第三周的课程中想讲的,这里依次讲解,小写代表一个样本,大写代表有m个样本。
第一组公式:和
这里Input为已知,因为z的维度是,显然也是,a和z本来就是同维度的,只是使用了激活函数而已,这里就应该是简单的矩阵点乘;同理 A,Z。
第二组公式:和
对于W,z而言,W的维度是,的维度是,的维度是,很显然就是将a转置就可以了;至于W和Z,这里无非是将z的维度变为,增加到m个样本,而A也变为,此处求解dW时就是将这些样本每一个作用的结果累计求和然后取平均的结果。
第三组公式:和
db的维度是,和dz的维度一样,而dZ只是多个样本的结果,列变成了m,此时只需要对行进行求和即可。
第四组公式:和
其中对应着,即维度为,的维度为,的维度为,这样就是要转置即可;对应的如果样本变为m后,的维度为,的维度为,这样和之前没有什么变化。
下面就用python实现一个深层神经网络的一般模型
大作业
搭建一个多层的神经网络,然后对cat进行预测。
作业地址:
Building your Deep Neural Network - Step by Step v5
Deep Neural Network - Application v3
分为初始化函数,前向函数,成本函数,反向函数,参数更新这几个部分。
初始化
前向传播
成本函数
反向传播
参数更新
详细请参考作业地址

