神经网络和深度学习[1-2]
神经网络和深度学习[1-3]
神经网络和深度学习[1-4]
改善深层神经网络:超参数调试、正则化以及优化【2-1】
改善深层神经网络:超参数调试、正则化以及优化【2-2】
改善深层神经网络:超参数调试、正则化以及优化【2-3】
结构化机器学习项目 3
Ng的深度学习视频笔记,长期更新
1.1 Why ML Strategy?
如下图所示,我们可以从以下几个方面来优化我们的模型:搜集更多的数据,搜集更多的反例,让梯度下降运行更久,使用Adam算法…
1.2 Orthogonalization
就讲了一点,正交化的意义,就像电视图像一样,如果说电视图像太宽,调整那个控制宽度的旋钮就可以了;在机器学习中,如果可以观察系统,知道哪一部分是错误的,它在训练集上做的不好,在开发集上做的不好,或者是在测试集上做的不好等等,然后去调节对应的旋钮,刚好可以解决该问题。
1.3 Single number evaluation metric
Precision(查准率)和Recall(查全率)的定义
Precision:分类器得出的结果与实际结果的重合度(比如分类猫中分类器得出的结果为猫,其中有95%的真猫,说明该分类器的查准率为95%)
Recall:表明实际为猫的图片中,有多少被系统识别出来。
如下面图所示,我们需要在A和B中选择一个分类器来作为最优的分类器,这里需要一个单一的数字评估指标,如下面的。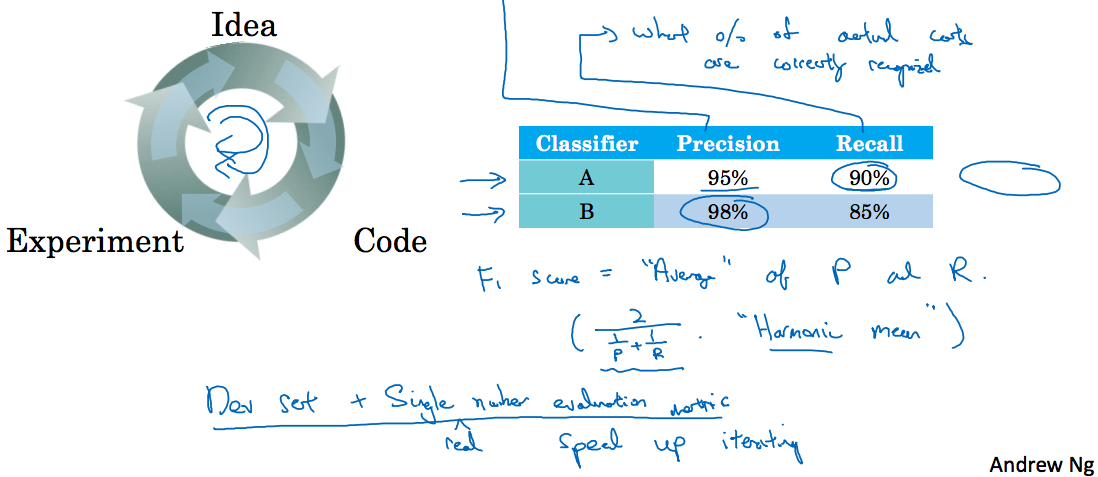
其中作为查准率和查全率的调和平均值,如下计算:
我们可以得到A分类器有一个更高的分数,假设F1分数是一个合理的计算结果,我们就可以淘汰B分类器。
1.7 When to change dev/test sets and metrics

如上图所示的模型,算法A由于某些原因把很多色情图像分类成猫,如果部署A,给用户推送猫的错误率虽然降低了很多,但是同时也会推送一些色情图片,公司不能接受这一点;但是算法B虽然有5%的误差,但它不会推送色情图片,所以从公司和用户的角度来看,算法B更为合理。用一个评估函数来表示这些:
其中的含义表示如果图片不是色情图片则为1,如果是得话,可以加大权重,比如10,或者100之类的,也可以将修改为。这样我们就可以用这个评估函数来更加合理的选择算法。
上面这个例子就是正交化的例子,我们在做机器学习的时候,第一步应该是清楚如何定义一个指标来衡量想做事情的表现。我么应该把机器学习任务看成两个独立的步骤,第一步就是设定目标,如何设定目标是一个独立的问题,看成一个单独的按钮,可以调试算法表现的旋钮,如精确瞄准。第二步是设定一个评估函数,比如上面的Error,然后再想如何优化系统来提高这个指标评分。
上面的例子中,A算法可能在评估函数上有一个很好的表现,但是在实际的测试集上却没有B算法好,我们就需要修改指标,或者我们使用的看法测试集。
1.10 Understanding human-level performance
Human-level error(人类水平误差)用来估计贝叶斯误差,即理论最低误差,不管是现在还是将来能够达到的最低值。
以医学图像分类为例,对于一个放射图像,假设一般人的误差是3%,普通医生的误差是1%,有经验的医生误差是0.7%,一个经验丰富的团队的误差是0.5%,那么我们可以认为人类水平误差为0.5,而贝叶斯误差小于等于0.5%。
假设对于上面的例子,我们的训练误差是5%,开发误差是6%,训练误差和人类水平误差之间的差值衡量了可避免的偏差,训练误差和开发误差之间的差值说明了学习算法的方差问题有多么严重,那么对于这个结果我们更应该修正模型的偏差,也就是加更多的神经元等;而对于训练误差为1%,开发误差为5%,那么我们更应该修正模型的方差;如果我们的训练误差是0.7%,而开发误差是0.8%,这里我们就很难做了,比如人类水平误差是0.5%,那么我们就该修正偏差,但是如果人类水平误差是0.7%,我们就要修正方差。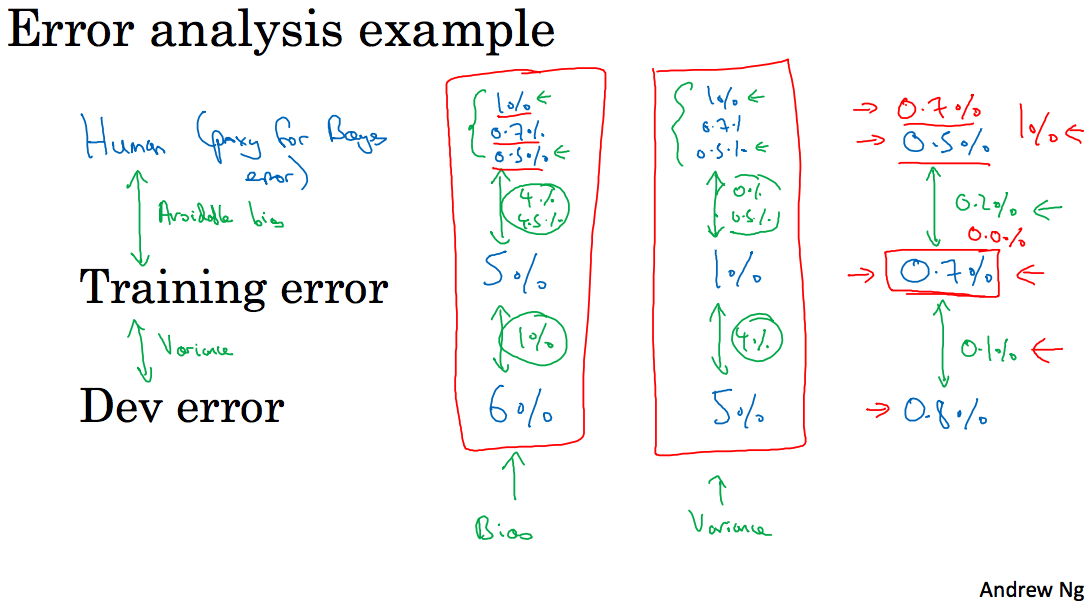
如上表明了当机器学习任务的接近人类水平的时候,就会发现其进展越来越困难。见下面这个图:
这里将一个团队的误差作为贝叶斯误差,左边的训练误差为0.6%,开发误差为0.8%,我们知道应该修正模型的方差;右边的图训练误差已经低于我们人类水平误差,我们不知道实际的贝叶斯误差是多少,如果是0.5%,说明模型过拟合了,但是如果贝叶斯误差是0.1%,说明我们需要修正的是偏差,这样我们就不知道如何优化我们的模型了,没有了明确的选项和前进的方向。
1.11 Improving your model performance
这一节是总结,对于偏差和方差应该采取哪些方法,如下图所示: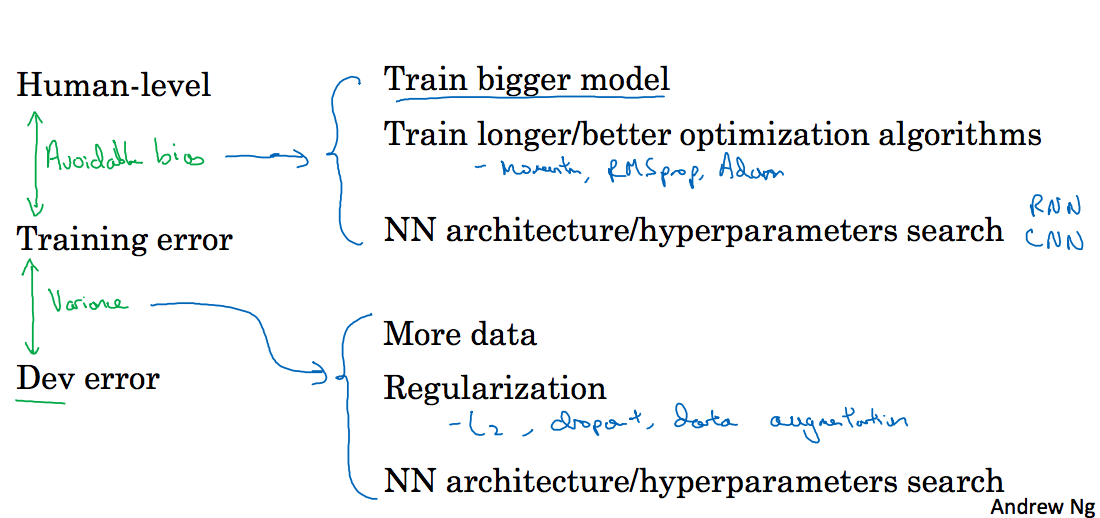
2.1 Carrying out error analysis
对于猫分类的例子中,对于出现的误差,假设你有几个改善猫检测器的想法,如改善针对狗图的性能,或者要注意那些猫科动物,它们经常被分类成猫,或者发现图像是模糊的,等等(发现一种方法可以更好的处理模糊图像),现在我们要对误差分析来评估这三个想法,可以建立如下的表格: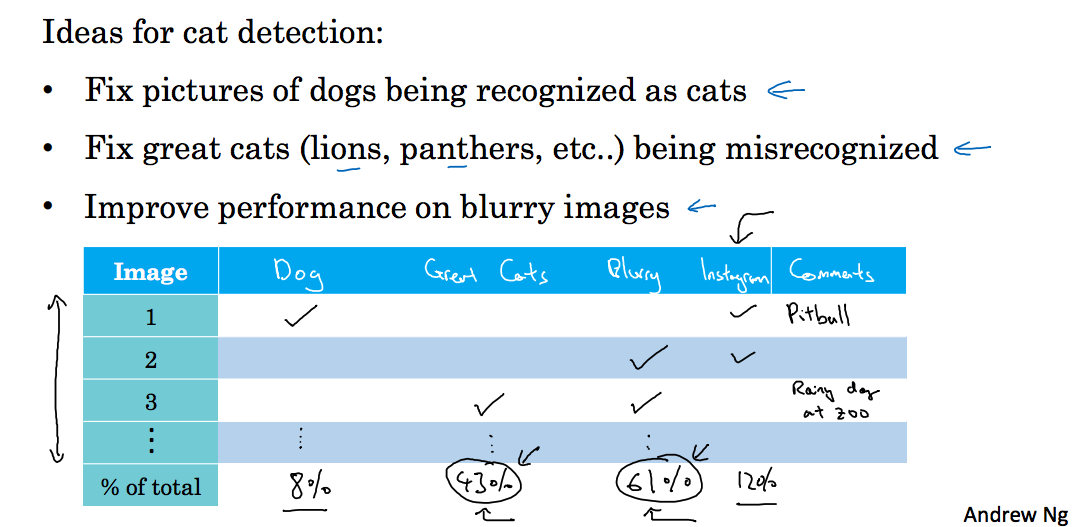
左边一列为要分析的图像集(错误集),第一行为我们要评估的想法(狗的问题,猫科动物,模糊图像),然后在对应的列上打勾,最后一行统计概率,这样我们就知道对于某一列的问题如果解决了对我们模型性能会有多大的提升。
看不下去了,感觉功力不够,吸收的太少了,有时间再慢慢看吧…

