神经网络和深度学习[1-2]
神经网络和深度学习[1-3]
神经网络和深度学习[1-4]
改善深层神经网络:超参数调试、正则化以及优化【2-1】
改善深层神经网络:超参数调试、正则化以及优化【2-2】
改善深层神经网络:超参数调试、正则化以及优化【2-3】
结构化机器学习项目 3
Ng的深度学习视频笔记,长期更新
3.2 Computing a Neural Network’s Output
如下图所示,在第二周中讲到的logistic回归的例子只是神经网络隐藏层中的一个节点而已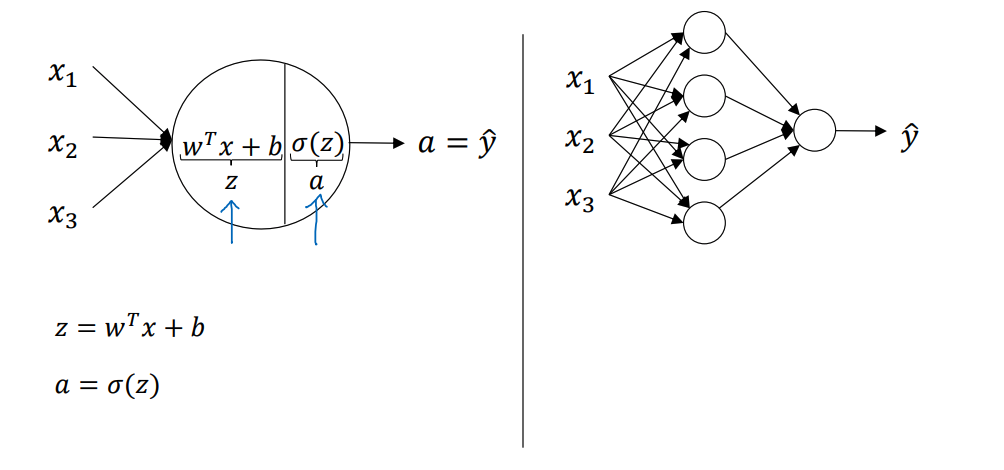
其中代表的是样本的特征,这里用向量这矩阵来形象的解释(主要是为了不使用for)
以单样本为例:
w矩阵行表示该层神经元个数,列表示样本特征个数,b向量长度为该层神经元的个数,即可表示为:
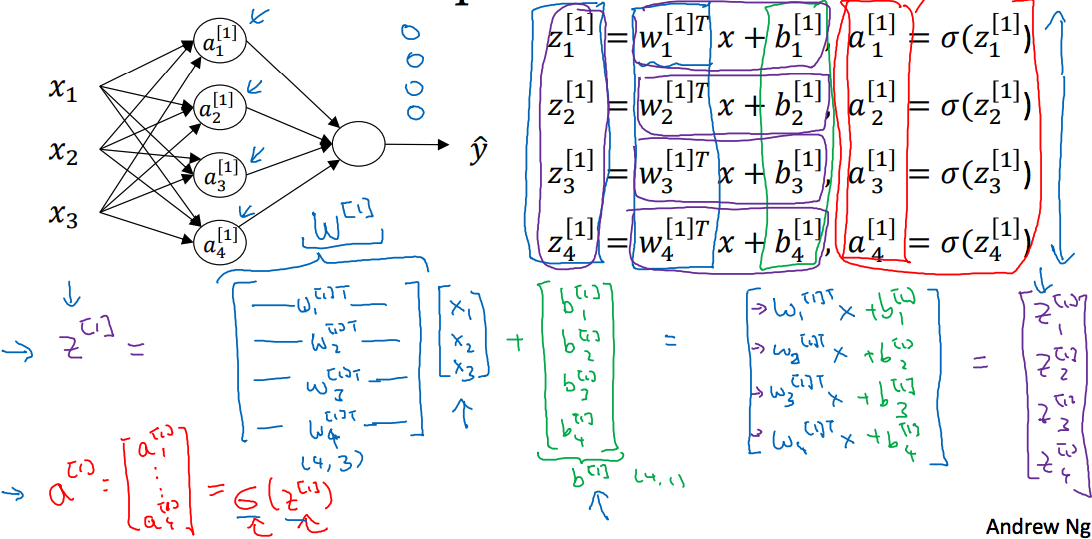
3.4 Vectorizing across multiple examples
那么对于多个样本,同样是上面那个神经网络,用矩阵去掉下面这个for:
m为样本个数,X矩阵(行为样本个数,列为样本特征个数),,,如下:
3.6 Activation functions
讲到了sigmoid,tanh,Relu,leaky Relu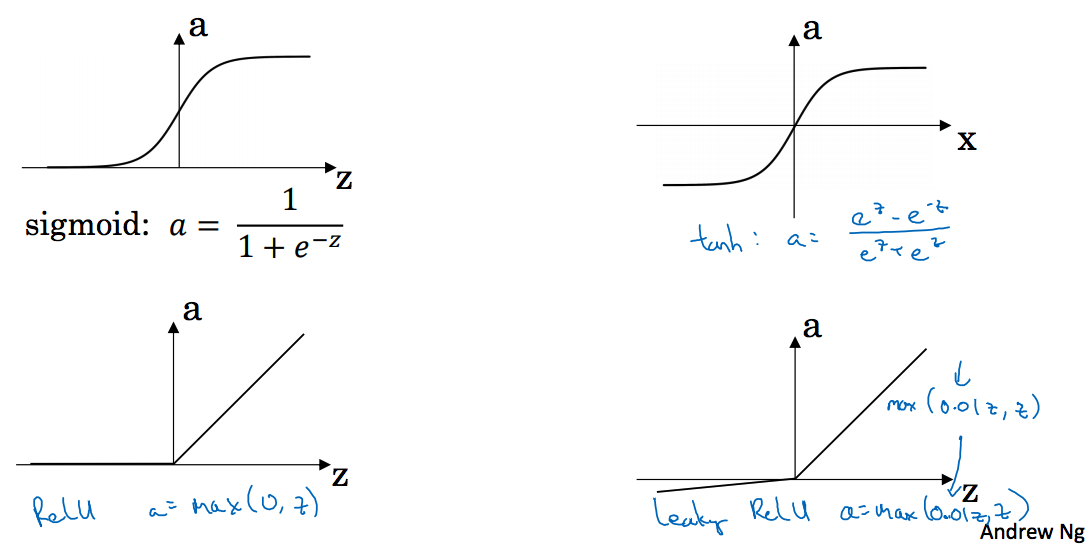
这里以这几个问题简单的讲解一下激活函数:为什么要使用激活函数,激活函数有哪些性质,各个激活函数有什么区别?
对于简单的样本分类可以使用线性拟合,但是对于复杂的样本,线性不可分的情况就需要引入非线性函数,也就是说对于神经网络中如果直接令的话,组合起来永远都是线性的,根本不需要多层网络;
激活函数被定义为处处可微的函数,几个概念,关于饱和,硬饱和,软饱和
饱和:当激活函数h(x)满足
称为右饱和
当激活函数h(x)满足
称为左饱和
硬饱和:对任意的x,如果存在常数c,当x>c时恒有 h′(x)=0则称其为右硬饱和,反之左硬饱和
软饱和:如果只有在极限状态下偏导数等于0的函数,称之为软饱和
Sigmoid函数
输出映射到(0,1)之间,可作为输出层,但是由于软饱和性,容易产生梯度消失,最终导致信息丢失,从而无法完成深层网络训练;而且反向传播求解梯度时涉及除法,计算量大;其输出不是以0为中心。[3点]
此处讲一下梯度消失是什么,为什么梯度消失就会导致信息丢失?
梯度消失就是当sigmoid非常接近0,1时,对应的梯度会非常的小,而如果神经网络的层数又非常大的话,由于梯度的最大值是1/4,反向传播导致连乘导致前面层的梯度会越来越小,近乎与随机,这样就起不到训练的效果,即信息丢失。
再讲一下Sigmoid输出不是zero-centered,而下面的tanh是zero-centered?
网上说的感觉有问题,也没看太明白,说Sigmoid在梯度下降时如果输入x全为正或者负,会导致下降缓慢,而tanh就不会,后面又说批量导入数据的话可以解决,我没太明白zero-centered,ng说使用tanh激活函数的平均值接近于0,当你训练数据的时候,可能需要平移所有数据,让数据平均值为0,使用tanh而不是Sigmoid函数,可以达到让数据中心化的效果,上层的结果接近于0而不是0.5,实际上让下一层的学习更方便[会在第二门课中详细讨论]
下面这段似乎更清楚了:
Sigmoid outputs are not zero-centered result, in later layers of processing this would be receiving data that is not zero-centered. This has implications because if the data coming into a neuron is always positive, then the gradient on the weights w will during backpropagation become either all be positive, or all negative. This could introduce undesirable zig-zagging dynamics in the gradient updates for the weights, and that will be inconvenience.
参考:Why would we want neuron outputs to be zero centered in neural networks?
tanh函数
比Sigmoid函数收敛速度更快,和Sigmoid相比输出是以0为中心,同样由于软饱和性会产生梯度消失。
ReLU函数
相比于Sigmoid和tanh,ReLU在SGD中能够快速收敛,运算简单,缓解了梯度消失的问题,提供了神经网络的稀疏表达能力;但是随着训练的进行,神经元会出现死亡,权重无法更新,即从该时刻起,神经元输出将永远是0【不幸的初始化,或者learning rate太高】
其输出不是zero-centered
ReLU目前仍然是最常用的activation function
Leaky ReLU函数
为了解决ReLU的Dead ReLU Problem,提出ReLU的前半段设置为0.01x而不是0,在实际操作中并没有完全证明Leaky ReLU总是好于ReLU的
softmax函数
用于多分类神经网络的输出
如上公式,表明那个大于其它的,那么这个分量就逼近于1,然后选取最大的那个作为输出,这里选择指数是因为要让大的更大,并且需要函数可导。
参考
CS231N-Lecture5 Training Neural Network
聊一聊深度学习的activation function
深度学习中的激活函数与梯度消失
浅谈深度学习中的激活函数
3.9 Gradient descent for neural networks
继续上图,仍旧以前面的神经网络为例,前面讲到正向传播过程,此处是反向传播过程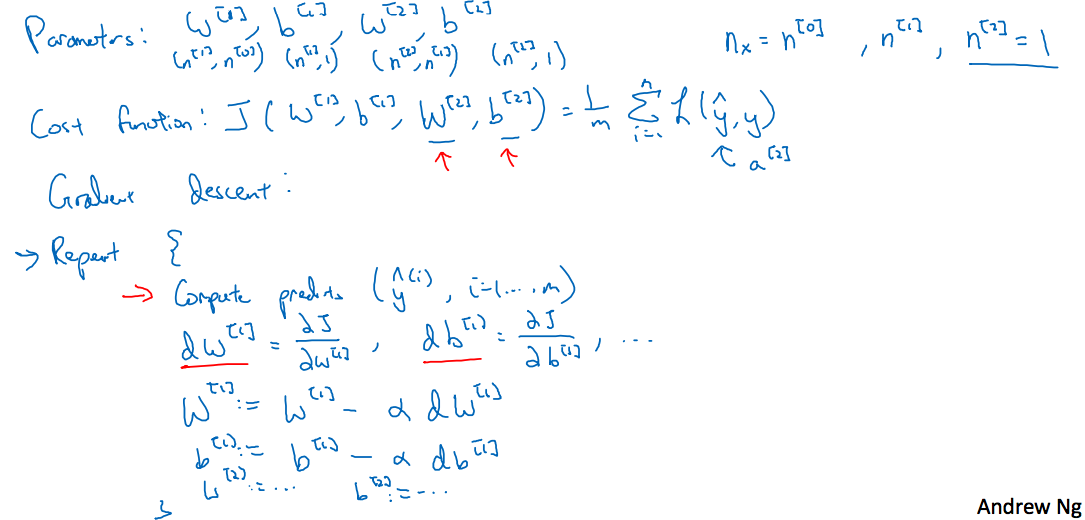
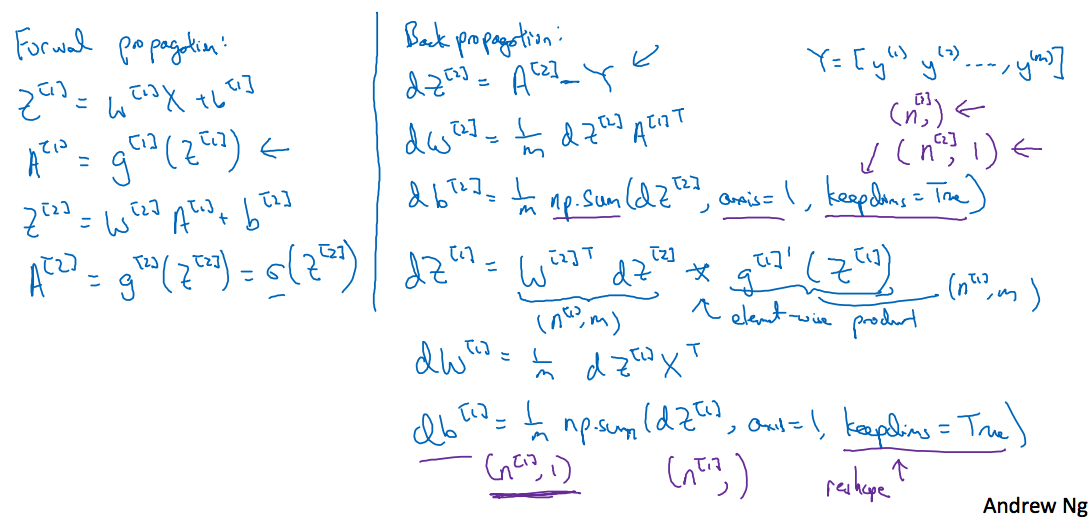
讲的很清楚了,这里表示的是第i层的神经元个数,这样对应的各参数维度有
关于求解梯度,可以参考第二周的详细笔记,这里仅对解释(视频中讲到第二层的激活函数使用Sigmoid函数,第一层的激活函数设置为g(x),与前面前向传播中都使用Sigmoid函数的不同,一般来说对于二分类最后一层使用Sigmoid函数,而其它层应该尽量避免使用Sigmoid函数)
这里dz和z的维度相同,因此在计算梯度的过程中注意维度
下面是自己用python实现仅含有一层隐含层的神经网络前向反向传播算法,激活函数均为Sigmoid函数
虽然照着公式写出了代码,但是这里我还是想详细的讲述一下该神经网络反向求导的过程
见第4周,用维度来讲解,不过如果要想搞清楚其中原理还是使用纯变量来计算最后再转化为矩阵看效果,不过这样得不偿失!
最后讲到了初始化的问题,为什么不能全部初始化为0,这里原因是因为如果全部初始化为0后,导致输出的结果一样,而且在反向传播的过程中每层的dw会一样,导致每层w相同,无法拟合模型
大作业
地址:Planar data classification with one hidden layer v4
其中planar_utils文件请参考deep-learning-specialization-coursera
数据集X维度为(2,400),Y的维度为(1,400),这里先使用sklearn中的logistic回归来拟合
输出如下: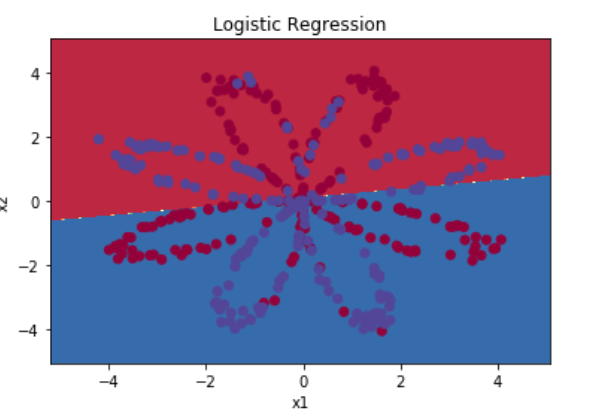
Accuracy of logistic regression: 47 % (percentage of correctly labelled datapoints)
显然logistic回归在非线性数据的分类上效果很差,下面用含一个隐藏层的神经网络来实现该数据集上的分类,下面是函数代码及解释过程,更详细的说明请参考原文
初始化参数
Instructions:
- Make sure your parameters’ sizes are right. Refer to the neural network figure above if needed.
- You will initialize the weights matrices with random values.
Use: np.random.randn(a,b) * 0.01 to randomly initialize a matrix of shape (a,b). - You will initialize the bias vectors as zeros.
Use: np.zeros((a,b)) to initialize a matrix of shape (a,b) with zeros.
|
|
前向传播
成本函数
Instructions:
- There are many ways to implement the cross-entropy loss. To help you, we give you how we would have implemented :
logprobs = np.multiply(np.log(A2),Y)
cost = - np.sum(logprobs) # no need to use a for loop!
(you can use either np.multiply() and then np.sum() or directly np.dot()).
反向传播函数
Tips:
- To compute dZ1 you’ll need to compute . Since is the tanh activation function, if then . So you can compute using (1 - np.power(A1, 2)).
|
|
参数更新
给出两张图,对应着learning_rate
The gradient descent algorithm with a good learning rate (converging) and a bad learning rate (diverging). Images courtesy of Adam Harley


|
|
模型训练
模型预测
As an example, if you would like to set the entries of a matrix X to 0 and 1 based on a threshold you would do: X_new = (X > threshold)
比如下面的Sigmoid输出后,要求其值大于0.5的输出1,否则输出0
训练+预测+结果
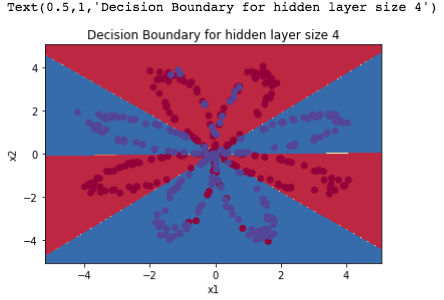
Accuracy: 90%
继续做了一个测试,来看隐藏层神经元的个数对神经网络训练的影响,这里就不放图片了
Accuracy for 1 hidden units: 67.5 %
Accuracy for 2 hidden units: 67.25 %
Accuracy for 3 hidden units: 90.75 %
Accuracy for 4 hidden units: 90.5 %
Accuracy for 5 hidden units: 91.25 %
Accuracy for 20 hidden units: 90.5 %
Accuracy for 50 hidden units: 90.75 %

