PRF
精确率:在预测为正确的样本中实际正确的样本的占比
召回率:在实际正确的样本中被预测为正确的样本的占比
F1值:可以思考并联电阻
如下图所示: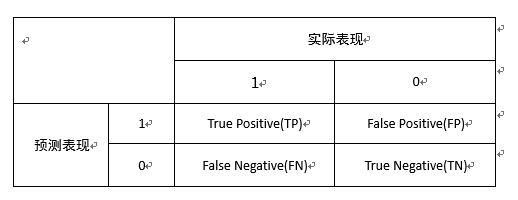
这幅图更加直观: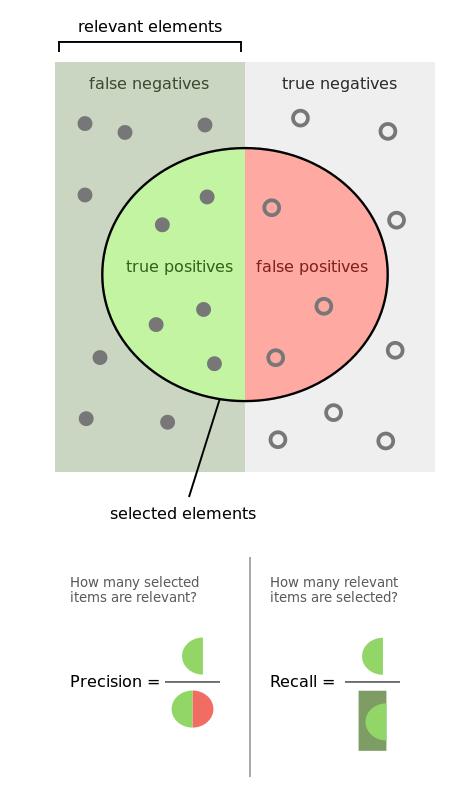
ROC和AUC
ROC曲线的横坐标为FPR,纵坐标为TPR
FPR:实际中的负样本有多少被预测为正样本
TPR:实际中的正样本有多少被预测为正样本
绘制曲线ROC的方法是:模型会对不同的样本输出一个分数,绘图时,设定阈值k,将分数低于该阈值的判定为负样本,将分数高于该阈值的判定为正样本,这样就会有FPR和TPR值,继续设定阈值k,又会有一个坐标,将这些坐标值连起来就是ROC曲线
ROC曲线下的面积就是AUC
如下图所示: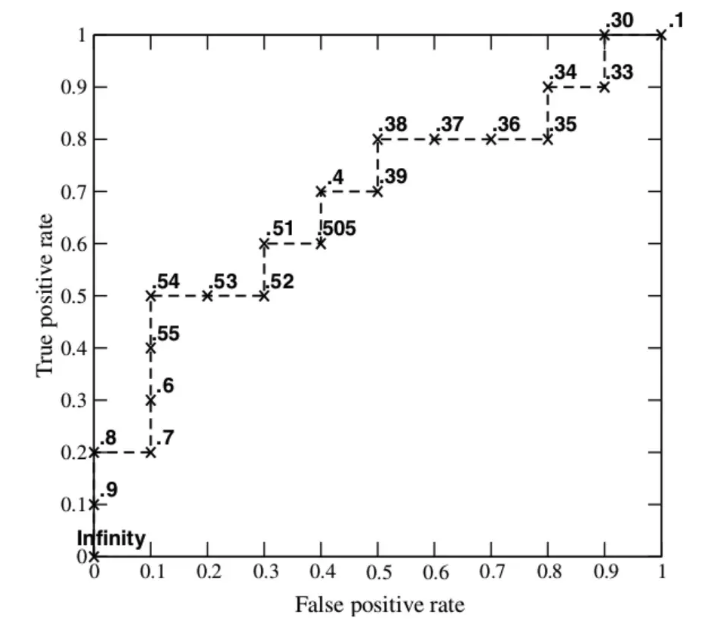
这里我理解一下:
阈值是从1开始,到0结束,阈值为1的时候,将分数小于1的样本归为负样本,可以知道一般模型对样本的打分都是小于1的,只能说是无限接近1,因此其结果就是样本全部被预测为负样本,那么FPR和TPR就为0,随着阈值的减小,比如阈值等于0.9,将分数小于0.9的归为负样本,将分数大于0.9的归为正样本,也就是说如果模型足够好,这个点会越靠近(0,1)点,也就是最后ROC曲线下的面积越大
AUC的物理意义:假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率
AUC和准确率
对于不平衡的样本,准确率是没有用的,比如数据集中垃圾邮件占比10%,正常邮件占比90%,如果一个模型将所有的样本都认为是正常邮件,准确率是90%,但是模型没有一点分类效果
PRC和ROC的对比
一般考虑样本不均衡的情况,分两种情况
- 正样本远大于负样本
比如数据集中正负样本比例为,正样本:负样本=1000:1,将阈值不断下降:- 对于PRC曲线,刚开始可能只有100个样本被判为正样本,之后会越来越多,这样P永远是1,R在不断增加,好的分类器和坏的分类器的PRC曲线无法区分
- 对于ROC曲线,纵坐标一直增加,横坐标基本不变
- 正样本远小于负样本
拿垃圾邮件分类问题,垃圾邮件(正样本):正常邮件(负样本)=1:1000,将阈值不断下降:- 对于PRC曲线来说,也就是被判为垃圾邮件的比例越来越多,P会越来越低,R为1,如果模型比较好的话,曲线下降就比较缓慢,模型比较差的话,曲线下降会很陡
- 对于ROC曲线来说,纵坐标是召回率,一直是1,横坐标表示负样本中有多少被判为正样本(即正常邮件中有多少被判为垃圾邮件),因为正常邮件特别多,即便是有几个被误判,其比值也非常小,因此对于好模型和坏模型来说,ROC曲线不会有太大的变化
上面分析的比较粗略,总之知道ROC和PRC的横坐标和纵坐标的意义即可,PRC考虑的是正样本的情况,ROC同时考虑了正负样本的情况,正因为这样,对于样本不平衡的数据集而言,ROC表现得更加稳定
数据不均衡的处理
从算法内部出发
- 损失函数加惩罚项
以三分类(类别名可标为0, 1, 2)为例,假设训练集三种类别数量分别为100000,1000, 100,其比例为1000:10:1。则在其损失函数对每类别添加权重weight = [1,10,1000](注意:是类别数量比重的倒序,即数据少的weight需要大一点) - 改用其他机器学习算法
比如决策树就不会受到不均衡数据的影响(这个实质就是加惩罚项,存在质疑) - 修改算法
也就是说如果某一类样本特别多,就降低这类样本的阈值,比如A,B样本,如果A样本远大于B样本,模型对每个样本都会有一个分数,一般阈值设置为0.5,这里如果B样本比较少,大概率一个样本是A的可能性更高,那么将阈值调为0.6或者更高,即大于0.6的才为A样本。[纠正模型对训练数据不平衡的误判]
- 损失函数加惩罚项
从数据的角度
- 收集更多数据以补充小样本数据从而达到平衡
- 过采样:拷贝一部分样本偏少的数据多份
优点:不会导致信息丢失,表现优异
缺点:增加了过度拟合的可能性 - 欠采样:删除一部分样本偏多的数据,以达到平衡
优点:当数据集很大时,它可以通过减少训练数据样本来帮助改善运行时间和存储问题
缺点:丢弃了对于构建分类器可能很重要的信息,采样的结果可能是有偏采样
改变评价指标
PRF,ROC- 集成技术
主要的目标是改善单个分类器的性能
如下图所示: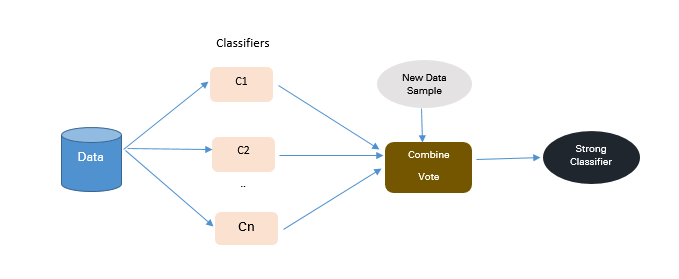
bagging
优点:
(1)提高机器学习算法的稳定性和准确性
(2)减少差异
(3)克服过拟合
(4)改进分类器的错误分类率
(5)在嘈杂的数据环境中,bagging方法优于boosting方法[也就是说模型的鲁棒性强]
缺点:只有当基本分类器开始并不是很差的时候才有效,如果基分类器效果本来就差,最后的结果可能更差
boosting
Boosting是一种集合弱学习器的集合技术,可以创建一个能够做出准确预测的强大学习器。
弱学习器:当数据的微小变化引起分类模型较大的变化时,分类器学习算法模型被认为是弱学习器
在下一次迭代中,新分类器将更多权重放在那些在上一轮中被错误分类的情况中,有如下几种Boosting方法:- AdaBoost
优点:实现起来简单; 适用于任何分类问题,不容易过拟合
缺点:对嘈杂的数据和异常值敏感 - GBDT
拟合残差,通过梯度下降最小化损失函数
缺点:需要微调三个参数:收缩参数,树的深度,树的个数,需要对这些参数进行适当训练以获得良好的拟合,如果参数未能正确调整,可能会导致过度拟合。 - XGBoost
是GBDT的一种先进且高效实现
优点:它比GBDT快了10倍,因为它实现了并行处理,它非常灵活,用户可以定义自定义优化目标和评估标准 (不太懂,参考3)
- AdaBoost

