过拟合和欠拟合本来也是比较简单的问题吧,但是比较常见,经常会被问到,这里总结一下,涉及到的东西比较多
方差和偏差
偏差:描述的是预测值的期望与真实值之间的差距,其针对的是一个模型,也就是说bias越小,模型的拟合能力越强(可能会导致过拟合),反之,拟合能力越低(可能产生欠拟合)
方差:描述的是预测值的变化范围,离散程度,针对的是多个模型,也就是说比如使用不同的批次训练模型,然后用这个模型预测测试集中的某个点,看各个模型对该点预测的离散程度。我们希望从数据集中采样小批量数据(同分布)后,训练的模型对测试数据的预测基本一致,即方差小
从上面的定义可以知道偏差越小,模型的拟合能力越好,模型也越复杂,就会导致模型出现过拟合的现象,过拟合也就是说模型学习到了很多不该学习的特征,即模型过分依赖于数据,同分布的不同数据训练模型后对测试数据预测的结果相差比较大,即方差大,这两者是相互约束的
如下图所示: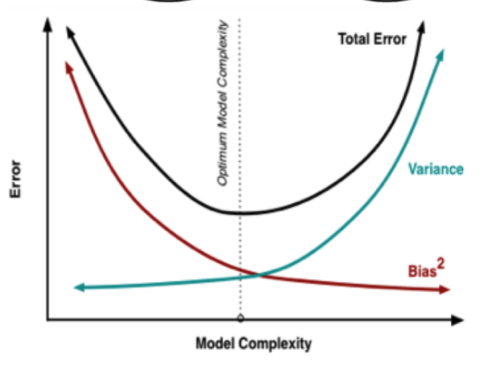
这里出现了四种情况,可以分为两个大类:
低方差,高偏差和高方差,高偏差
高偏差肯定是有问题的,模型不够复杂,也就是需要学习更多数据的特征
高方差,低偏差和低方差,低偏差
高方差,低偏差的问题在于模型过多的学习数据的特征了,导致过拟合了,需要降低模型的复杂度,这样依赖偏差就会有所增加,而方差会下降
低方差,低偏差是理想情况
过拟合的原因及解决方案
出现过拟合的原因:
- 在使用抽样方法对样本进行抽取的时候,抽出的样本数据不能有效代表业务场景
- 样本中噪音数据干扰过大,使得模型记住了噪声特征
- 参数过多,模型复杂度过高
- 决策树不剪枝
解决方案:
- L1,L2正则
- 适当的stopping criterion
- 交叉验证:当数据较小的时候,是用来减轻overfitting最好的方法
- dropout
- 加入噪声:提高模型的鲁棒性
- 集成方法
L1和L2正则
先来看一下为什么出现过拟合,如下图所示,随着训练过程的进行,模型的复杂度增加,在training data上的error渐渐减小,但是在验证集上的error却反而渐渐增大,因为模型过拟合了:
大概区分一下L1和L2:
L1和L2正则:
● L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为
● L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为
下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到:
● L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
● L2正则化可以防止模型过拟合(overfitting),即权重衰减
L1正则 (稀疏特征)
在损失函数后面加上所有权重w的绝对值和
当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
L2正则(权重衰减)
L2正则化就是在代价函数后面再加上一个正则化项:
如上,就是权重衰减的来由
L1和L2都是在让权重减小,那么问题是为什么权重变小后就能解决过拟合的问题:
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。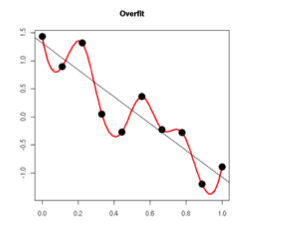
上面是从公式的角度出发来理解特征稀疏,权重衰减,下面用图示的方法理解(个人倾向前一种):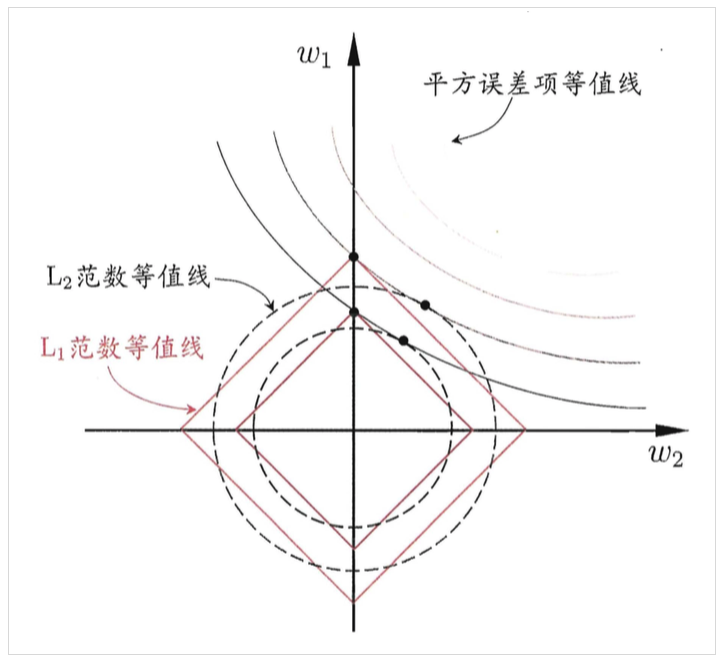
假设模型需要学习的参数只有两个w1,w2,实弧线代表的是经验风险(即损失函数的前面一项)的等高线,其随着w的变小而变大,红线和虚线代表正则项,随着w的变大而变大,我们的目标是找到他们的交点的这些点,选出使它们整体值最小的点,由图可知L1的交点更容易发生在坐标轴上,而L2则不同。
交叉验证
交叉验证就是将样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。
交叉的含义就是某次训练集中某样本可能成为测试集中的样本
交叉验证分为三种:
简单的交叉验证
将样本数据分为两部分(一般70%训练集,30%测试集),然后用训练集来训练模型,在测试集上验证模型及参数。[并没有达到交叉的效果]
优点:只需要将原始数据打乱后分成两组即可
缺点:没有交叉;随机分组,验证集分类的准确率与原始数据分组关系很大;有些数据可能从未做过训练或测试数据,而有些数据不止一次选为训练或测试数据。
S折交叉验证
S折交叉验证会把样本随机分成S份,每次随机选择S-1份作为训练集,剩下的一份作为测试集。
如下图所示: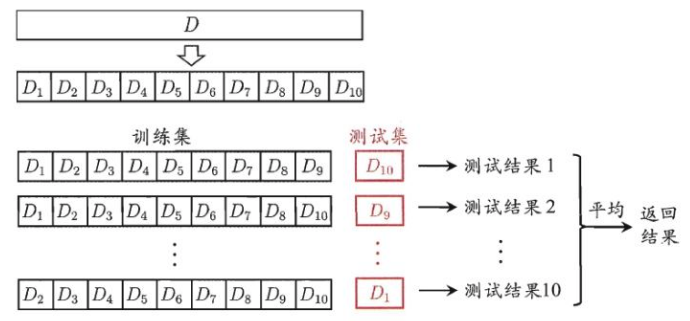
k的选取:数据量小的时候,k可以设大一点,数据量大的时候,k可以设小一点
这里k的选择考虑两种极端情况:
- 完全不使用交叉验证,即k=1,模型很容易出现过拟合【可以理解为模型学习了全部数据的特征,导致模型对训练数据拟合得很好,即偏差很小,但是实际上有些特征是没有必要学习的】,结果就是低偏差,高方差
- 留一法,即k=n,随着k值不断升高,单一模型评估的方差逐渐加大而偏差减小(即趋于出现过拟合,因为又用到了全部数据),而且计算量也会大增
总之,使用部分数据集肯定相对于全部数据集而言,偏差变大了,但是降低了方差,说白了k的选取就是偏差和方差之间的取舍
留一交叉验证
是第二种情况的特例,当S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一样本来验证模型的好坏。[主要用于样本非常少的情况]
自助法
如果样本实在是太少,可以使用自助法(bootstrapping),有放回的采样n个样本组成训练集(有重复的),没有被采样的作为测试集
交叉验证的目的是:
- 根本原因是数据有限,当数据量不够大时,如果把所用数据都用于训练模型,容易导致模型的过拟合,交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合
- 通过交叉验证对数据的划分+对评估结果的整合,可以有效降低模型选择中的方差。【为了得到可靠稳定的模型】
n问
- 为什么正则化能缓解过拟合
- L1和L2损失的区别,为什么L1是稀疏的,从线性规划角度描述
- 什么是过拟合,为什么会出现过拟合,怎么解决
- 各种正则的对比

