Abstract
ResNet是一个新的方法对于训练非常深的神经网络,使用身份映射用短连接。ResNet在ImageNet上实现了一个最好的表现,但是residual learning在噪声的自然语言处理任务上仍旧不能表现得很好,在这片论文中,我们设计了一个新颖的卷积网络,使用residual learning,并调查了它在远距离有监督的噪声关系提取任务中的影响。与流行的说法中ResNet只适合非常深的网络相反,我们发现我们只使用9层的CNN,,并使用identity mapping可以明显的提高远距离有监督的关系提取的表现。
Introduction
关系抽取任务是预测出句子中实体的关系和属性,比如给出一个句子:
Barack Obama was born in Honolulu, Hawaii
关系分类器的目标是预测关系“bornInCity”,关系抽取是建立知识图谱关系的一个重要部分,对NLP的任务中比如结构查询,语义分析,问答,总结等至关重要。
对于关系提取的一个主要的问题是缺乏标记的训练数据,在最近几年,distant supervision出现作为关系提取最流行的方法,它使用知识库事实在未标签数据中选择一系列噪声实例。在所有针对distant supervision的机器学习方法中,CNNs实现了最好的表现,Zeng et al. (2015) proposed a piece-wise max-pooling strategy to improve the CNNs. Various attention strategies (Lin et al., 2016; Shen and Huang, 2016) for CNNs are also proposed, obtaining impressive results
然而这些模型大多数掩盖了CNNs,典型的就是只使用一层卷积和一层全连接层,这里不明确的,是否更深的模型可以有一个更好的表现,在提取信息(distilling signals)从噪声输出中。
这篇文章,我们设计的基于residual learning的卷积网络,在噪声提取预测任务中将身份反馈给卷积层[不太懂???]
贡献在这三个点:
- We are the first to consider deeper convolutional neural networks for weakly-supervised relation extraction using residual learning;
- We show that our deep residual network model outperforms CNNs by a large margin empirically, obtaining state-of-the-art performances;
- Our identity mapping with shortcut feedback approach can be easily applicable to any variants of CNNs for relation extraction.
Deep Residual Networks for Relation Extraction
模型如下图: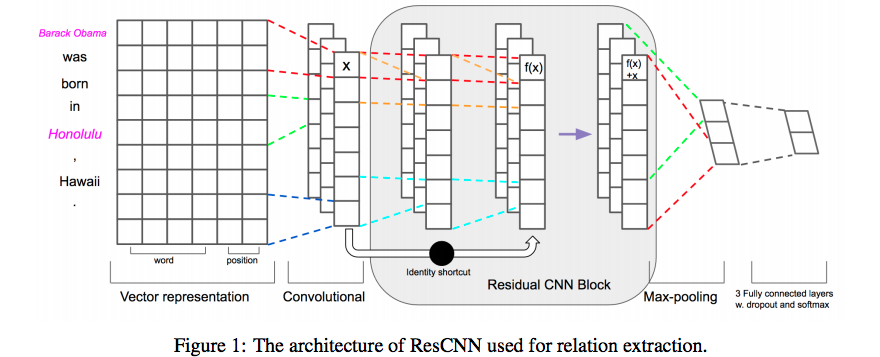
xi表示句子中的第i个单词,e1和e2是两个通信的实体,每一个单词将进入到两个嵌入查找表中得到单词嵌入WFi和位置嵌入PFi,然后进行连接表示为vi
单词嵌入中嵌入矩阵,其中V表示一个固定大小的词表。
在关系分类器中,我们关注的是发现实体对的关系,PF是当前词到第一个实体和第二个实体的相对距离的组合(a PF is the combination of the relative distances of the current word to the first entity e1 and the second entity e2.),比如:
in the sentence ”Steve Jobs is the founder of Apple.”, the relative distances from founder to e1 (Steve Job) and e2 are 3 and -2.
我们就转换相对距离为真实值向量,通过随机初始化查找表
,其中P是固定大小的距离集合,这里我们选择最大值emax和最小值emin来限制相对距离。
上图中的例子假定,有两个位置嵌入,一个是e1,一个是e2,最后连接所有单词的单词嵌入和位置嵌入,代表一个长度为n的句子作为一个vector:
where ⊕ is the concatenation operator and.
Convolution
这一部分讲的是卷积,一维卷积,就不复述了
Residual Convolution Block
Residual learning 连接低级别到高级别表示,解决了深度网络梯度消失的问题。在我们的模型中,我们通过应用短连接设计残差卷积块,每一个残差卷积块是一个两个卷积层的序列,每一个都使用ReLU激活函数,卷积核的大小是h,使用padding,使得大小和原来的一样。这里有两个卷积过滤器
具体如下:
For the first convolutional layer:
For the second convolutional layer:
Here are bias terms.
For the residual learning operation:
Conveniently, the notation of c on the left is changed to define as the output vectors of the block. This operation is performed by a shortcut connection and element-wise addition. This block will be multiply concatenated in our architecture.
Max Pooling, Softmax Output
这里一个特征被提取从一个过滤器中,提取的所有特征z=[c1,c2,..,cm]表示有m个过滤器。然后,这些特征通过全连接的softmax层,输出关系的概率分布。代替使用y = w · z + b 作为数据单元y在前向传播,使用dropout作用在z上。
Experiments
单词嵌入的维度为50,输入文本被扩充到固定的大小100,批次训练大小为64。
后面是两个对比,一个是resnet-cnn和其他方法对比,一个是resnet-cnn的自身对比。
具体参数如下: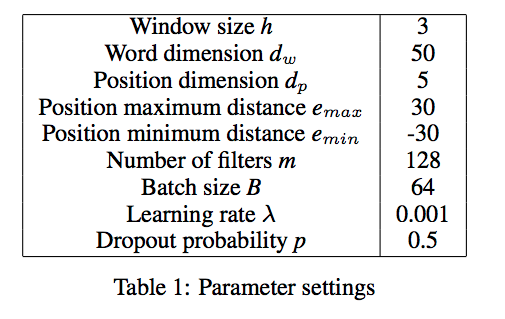
Conclusion
这篇论文介绍了一个深度的residual learning方法对distantly-supervised关系提取。我们展示了更深的关机模型帮助提取信息从噪声的输入中。使用shortcut connections和identify mapping,模型的表现得到了极大的提高。
问题
这里有两点问题不是特别清楚:
第一点是identify mapping到底是什么意思
第二点是初次看Relation Extraction任务,还没有特别清楚具体在做什么,参考了一下发现是分类任务,也就是说给定含有两个实体的句子,判断这个句子的关系是现有的关系中的哪一个关系???

