PyTorch是一个基于科学计算的python包,目标于两类受众:
- 在GPU上取代Numpy
- 一个提供最大的灵活性和加速的深度学习平台
字符生成任务目标:训练一些字符串,然后给定一个字符,输出一串字符串。
输入
字符生成和文本生成是一个问题,这里输入序列和目标序列是错位的
输入原始序列为一个字符串,需要将这个字符串映射为一个one-hot矩阵,构建一个字符词表n_letters,如下所示:
先是构建一个零矩阵,然后进行添加。
目标序列是错位的,最后一个字符用EOS添加,如下:
可以看到输出序列并不是一个one-hot序列
模型构建
这里自己实现RNN如下图: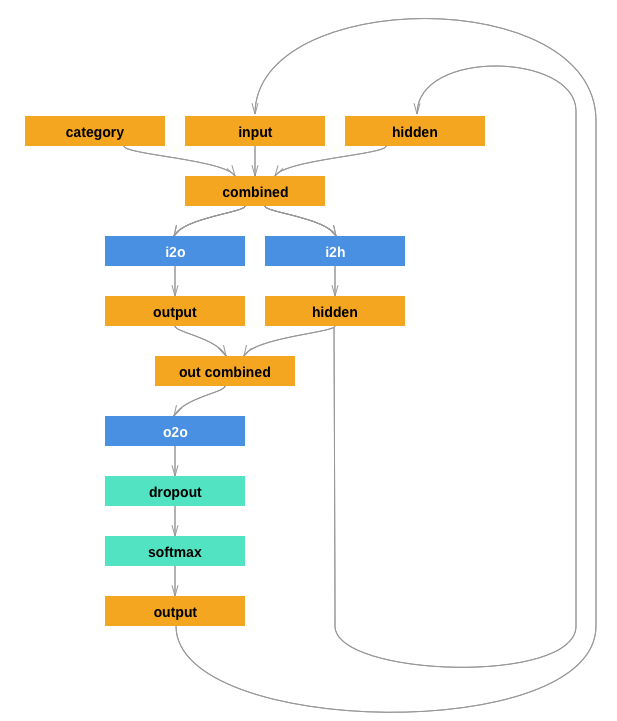
按照上图一步步写,如下:
nn.Linear表示的是一个线性矩阵变换,输入的两个参数代表矩阵W的维度,也就是进行y=Wx+b
使用的时候如forward函数,直接将输入作为参数[这是pytorch和一般的python的区别,第一步初始化参数,第二步传入执行函数参数,RNN也是一样,第一次传参进入到init中,第二次传参进入到forward中]nn.LogSoftmax表示对softmax进行log,参数dim表示的是对哪一维度进行计算,我这里举个例子:
如下代码:
input和output分别如下:
对第1维进行归一的结果[下标]
模型训练
代码如下:
这里对代码中的两点进行解释:
第一点是交叉熵函数 nn.NLLoss
表示负对数似然损失,用于训练C个类别的分类问题,可选参数weight是一个1维的Tensor,用来设置每个类别的权重,当训练集不平衡时该参数十分有用。
输入必须形如(minibatch,C)的2维Tensor,目标值是一个类别list。
需要在神经网络的最后一层添加LogSoftmax来得到对数概率,如果不希望在神经网络中添加额外一层,可以使用CrossEntropyLoss来代替,实质就是交叉熵。
具体计算如下:
也就是对应的值求和取平均,我这里举个例子:
第二点是input_line_tensor, target_line_tensor的维度:input_line_tensor的维度是[len(line),1,nletters],target_line_tensor的维度是[len(line)],然后经过`unsequeeze`进行扩维,变为[len(line),1],这样每次传入到rnn中的就是[1,n_letters]和[1,1]
迭代
代码如下:

