初入NRE,前期打算是先理解CRF,以及CRF,HMM,贝叶斯,最大熵之间的关系,然后用CRF实现命名实体识别,在结合BRNN+CRF训练,对比效果,之后在看看Attention,主动学习,对抗生成网络等等
use CoNLL 2002 data to build a NER system
这个是python-crfsuite对应的github上的example,我简单的过一遍,以及添加一些疑问,后续有时间解决。
先来看一下训练集,以一个句子为例:Melbourne ( Australia ) , 25 may ( EFE ) .
其表示形式如下,这里主要是用到了词性的信息:
然后看一下如何对每一个单词(x)进行找特征的,如下:
这个代码我有一些疑问,这里是对每个字生成特征,每个字一个特征集合,然后将一句话的每个字的特征集合组合成一个list,将这个作为一条输入,那么这些特征到底是如何组合的,等等内部细节不是很理解,有时间研究研究源码。
然后得到输入和输出数据:
然后就是开始训练
设置参数,这里不是特别懂,可以通过trainer.params()来查看有什么参数
训练
通过trainer.logparser.iterations打印具体参数变化情况
预测部分和评估部分参见[5]中给的网址,这里不做复述
后面提到了如何核查学习到的分类器:通过查看转移特征和状态特征的权重,得到最相关的和最不相关的转移特征和状态特征。
转移特征:
如下:
状态特征:
如下:
其实我是看到这个后,在想前面使用到的特征提取和这个的联系是怎么样的。如何将前面的特征变成了这里的转移特征和状态特征的。
这里我先搬出统计学习方法中CRF的一些定义
线性链的条件随机场的定义如下:
这里可以看到还是有简化的,比如的概率是只和有关,和全部的有关,条件随机场的解决办法如下,即其参数形式:

也是前面提到的问题,如何将这个公式和前面的特征联系上。。。
Chinese NER use CRF
这个需要安装python-crfsuite,本来很简单的事情,由于我的Mac中安装了Anaconda,导致电脑中有两个python3,结果默认使用pip3安装到了Anaconda的路径下,我pycharm中的是系统的python3,就一直没安装上,发现终端中使用的python3是Anaconda的,最后将~/bash_profile里面的Anaconda的python3路径export ...注释掉,在安装,就好了,(期间不知道为什么pycharm中不能直接安装)
这里和前面讲到的区别就是多加了字的结束与开始标志,然后是基于字符的。
首先我获得到的是如下训练集:
然后将其转为如下数据:
主要的方法就是将一句话组合起来,然后使用jieba分词,添加词性信息,添加每个字符处于词的什么位置信息(我这里可以理解为这个特征是因为词到字的转变需要)。代码如下:
然后就是添加特征:
主要代码和之前的都没有什么变化,这里就不复述了,具体代码参考我后面给出的github代码,会有全部的代码。
这里我给出精确率,召回率,F1 score分数,权重最大/小的15个转移特征和状态特征:
状态特征是X,转移特征是Y,状态特征也只由当前状态的前后和当前的决定。
Ner for Chinese clinical text
这里就没什么要讲的,只是想说明一些上面的一些问题,比如上面对于每个,只用到了前后一个字的信息,这里用到了前后两个的信息,而且这个是基于词的。
给定一些文本,其中有如下标签:
任务是将这些标记标出来。给出一些标准化的训练集如下:
此部分主要看一下特征处理这里:
由此,应该大体上理解了CRF中的特征如何使用了,其具体细节以及后续的进展可以参考[7]
A simple BiLSTM-CRF model for Chinese Named Entity Recognition
先给出LTP的NER的标准类型
NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义为
然后demo中给出了O, B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG,就很好理解了,B-PER表示的是人名的开头,I-PER表示的是人名的中间,后面的依次类推,就是地名,组织名。
然后其模型如下图所示: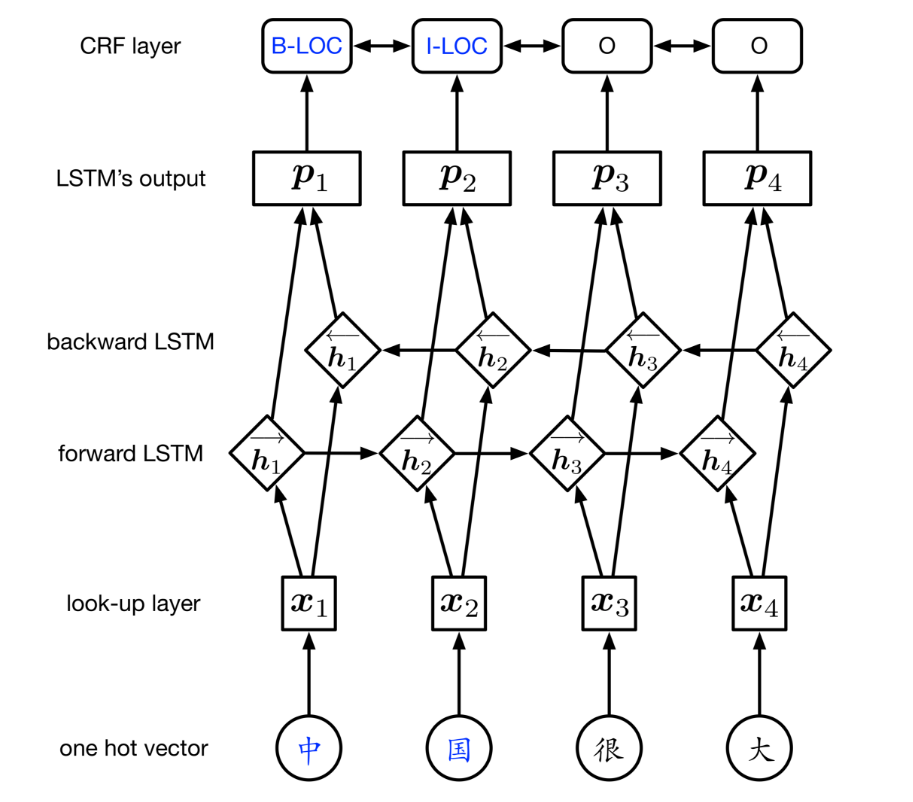
第一层look-up layer,目标是将字符表示从one-hot转为字符矩阵,代码中是随机的初始化矩阵,这里可以自己使用语言的知识来训练一个前置矩阵,后面参考的论文中有提到。
第二层BiLSTM layer可以有效的使用过去和未来的输入信息来自动的提取特征
第三层CRF layer为每一个字符打标签,这里不使用Softmax的原因是如果使用Softmax后,可能得到无语法的标记序列,因为softmax只能独立的为每个位置打标签,我们知道I-LOC不能够在B-PER后面,但是Softmax不知道,CRF层可以使用句级标签信息并对两个不同标签的转换行为建模。这句话不是很理解。
这里需要了解一下HMM,CRF的知识,我在后面讲到了
这里我想用HMM和CRF先将命名实体识别实现一遍,见前面。
NB/MaxEnt/HMM/MEMM/CRF
先讲一下判别式和生成式:
判别模型:直接将数据Y(label),根据所提供的X(fratures),学习,最后得到模型(划分一个比较明显的边界来区分label),也就是说判别模型是直接对P(Y|X)进行建模。对所有样本只构建一个模型,确定总体判别边界。
生成模型:先从训练样本数据中将所有的数据的分布情况摸透,最终确定一个分布,来作为我们输入数据的分布,即联合分布P(X,Y)(X包含所有的特征,Y包含所有的label),然后来了新样本数据,通过学习模型的联合分布,再结合新样本给的X,通过条件概率得到Y。生成模型在训练阶段只对P(X,Y)建模,对分类而言,要对每个label建模。
朴素贝叶斯
这里我们的y是一个单变量,而不是一个序列,而X是一个序列。下面详细介绍:
这里如果之间如果不是独立的,其每个取值都有很多种,然后进行组合的可能就会非常庞大,而朴素贝叶斯在此做了一个强假设,之间是相互独立的。
注意其假设是对在出现y的情况下x的一个概率的假设,如下: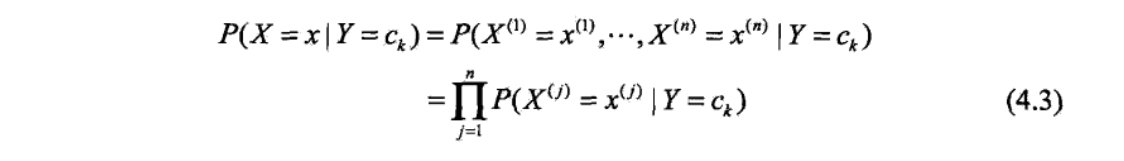
我们要求的后验概率通过贝叶斯转换后,就变为如下:
也就是我们需要找出在不同的y下X的概率最大的那个y
Logistic(Softmax) /MaxEnt
这两个是等价的,统计学习方法中也给出了证明,这里摘抄一个博客中讲到的:
即每条输入数据都会被表示为一个n维的向量,可以看成n个特征,而模型中每一类都有n个权重,与n个特征相乘后求和再经过Softmax的结果,代表这条输入数据分到这类的概率。
下面这段话,就是一个便利的转换:
这就是MaxEnt,其和Logistic的区别只是多加了几个特征而已(但是我不知道为什么要画两条线):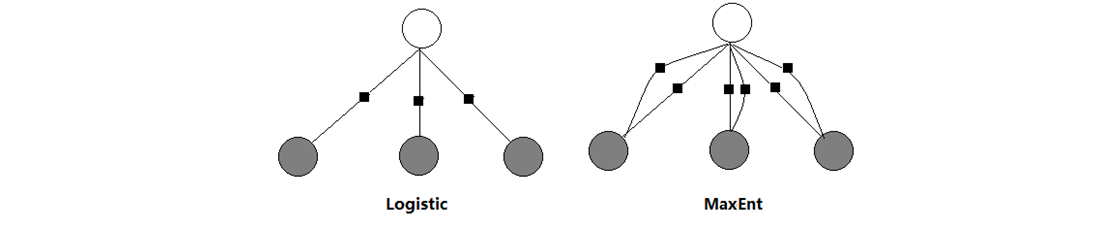
说一下这个图,上面的根节点是y标签,下面的叶子节点(灰色)是x
还是不太懂这两者的区别,后面有讲到为什么要画两条线
图表示
先用一张图展示如下: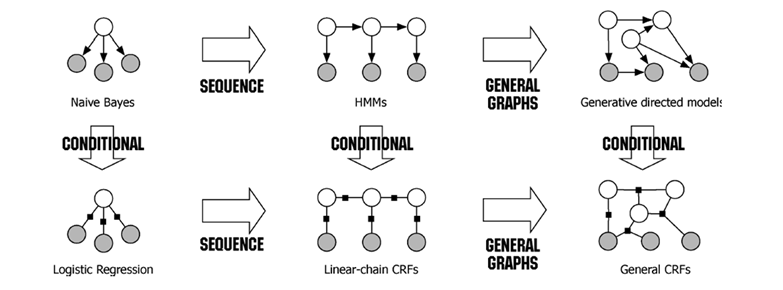
然后给出MaxEnt的模型: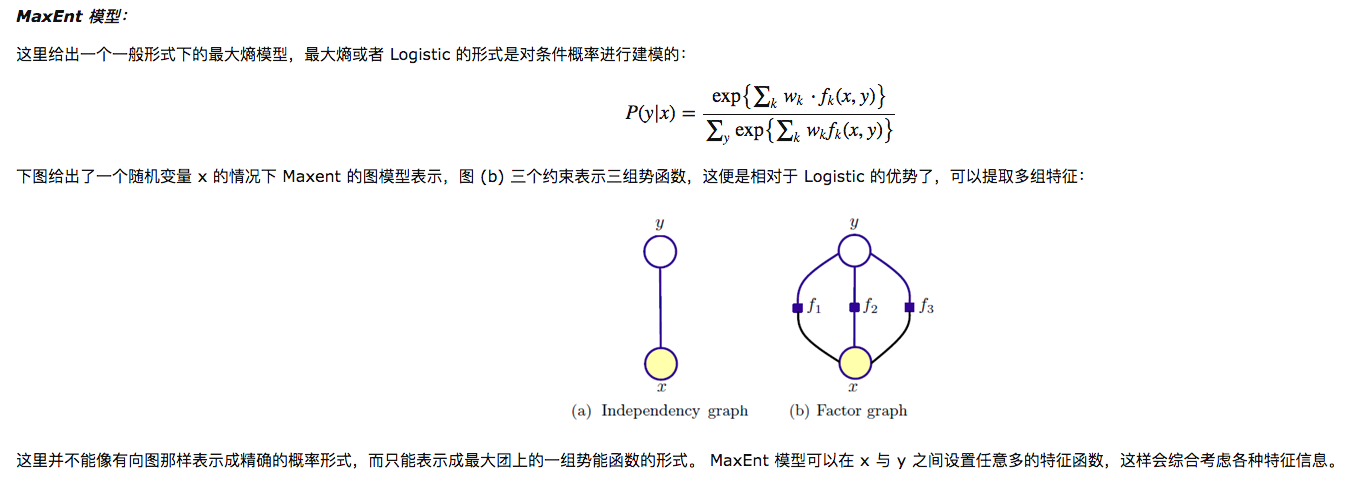
应该是解释了上面的疑问,也就是说MaxEnt会有多个势函数。
HMM是NB的扩展,CRF是MaxEnt的扩展,从上面的图也能看出来,此时的y变为一个序列Y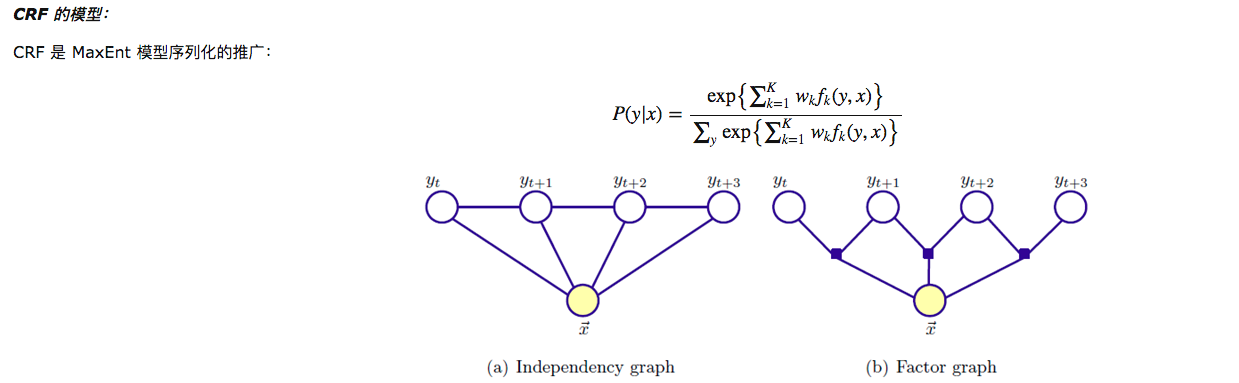
从这张图可以看出来(图示的不是特别好),我这里简述一下,其实很简单:对应每一个序列y,我们设定K组特征函数,和对应的权重向量,使用softmax的思想求解出概率最大的序列y即可。
HMM/MEMM/CRF
简单的来说HMM有两个假设,一个是输出观测值之间严格独立,二是状态转移过程中当前状态只与前一状态有关:
注意上面的话,说状态序列()作标记,标注问题是给定观测序列()预测其对应的标记序列(),记住这句话后,再来看网上给出的HMM模型图: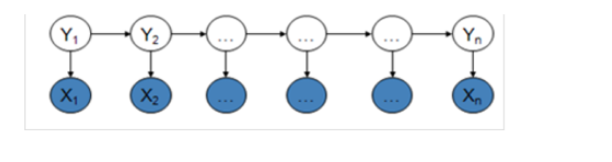
这个图上面的是观测序列,是状态序列,也就是标记。继续看统计学习方法中所举的例子,说给了4个盒子,从这4个盒子中选取一个盒子,然后从这个盒子中选出一个球,记下球的颜色,重复该过程5次,得到观测序列:
预测每个颜色的球最可能来自的盒子号的一个序列(状态序列),也就是说状态序列先一步观测序列。
由于是生成模型,我们用朴素贝叶斯的方法对其进行分析:
从这个公式中看上面这个模型图,箭头的方向也就不会别扭了吧。HMM先到这,再来看MEMM。
MEMM克服了观测之间的严格独立性,给出的图如下: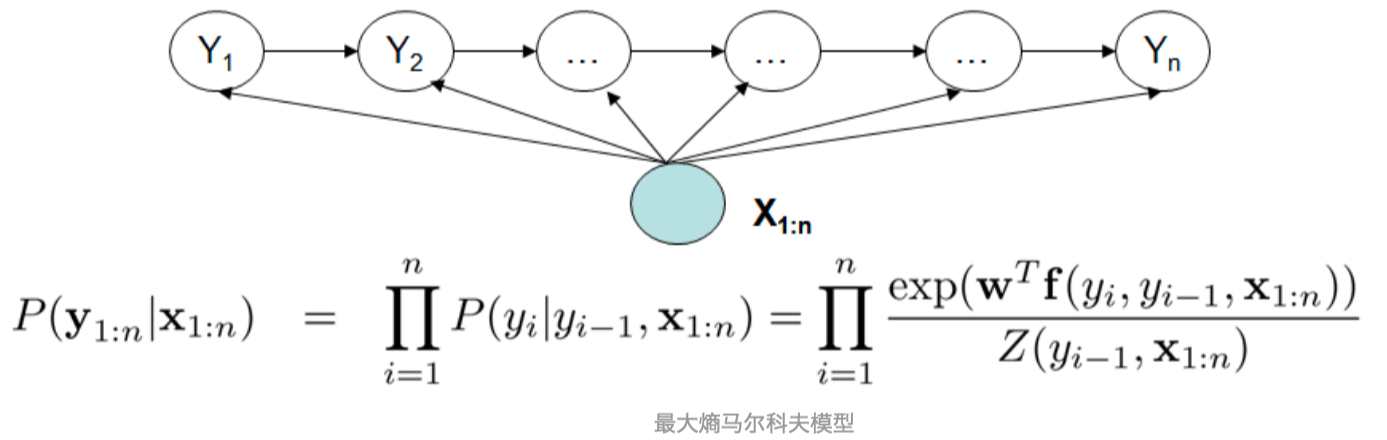
关于这个克服了观测之间的严格独立性,我的理解是状态由之前的只由决定变为由一起决定。
MEMM是局部归一化,会出现标注偏置的问题。CRF使用全局归一化,解决了标注偏置问题。具体的看下面MEMM和CRF的公式即可:
可以看到MEMM在求解状态序列时,是分每一步来求解的,而每一步的求解过程中都使用了softmax进行归一化,对比CRF,列出所有可能的状态序列,进行全局softmax归一化。那么偏置在何处呢,看下面这个例子: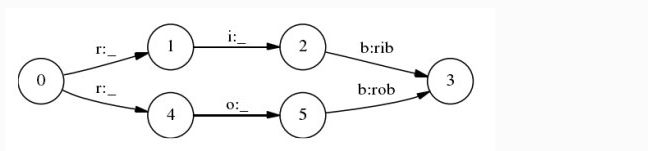
上图是一个简化的状态转移图,假设过程0->1出现的次数多于过程0->4的次数,但是过程4->5出现的次数远大于过程1-2出现的次数,或者说过程5->3出现的次数远大于过程2->3出现的次数,使用MEMM的话,不管过程1->2,4->5,2->3,5->3它们之间出现的次数如何,归一化的结果都是1,也就是说上述情况下,序列0-1-2-3出现的概率大于序列0-4-5-3出现的概率。但是CRF就不一样了,略。
参考
1.A simple BiLSTM-CRF model for Chinese Named Entity Recognition
2.LTP文档
3.Logistic 最大熵 朴素贝叶斯 HMM MEMM CRF 几个模型的总结
4.ChineseNER
5.Let’s use CoNLL 2002 data to build a NER system
6.Ner for Chinese clinical text
7.Evaluation Tasks at CCKS 2017
8.HMM、MEMM和CRF的学习总结
9.MEMM标注偏置问题

