结合公司的项目看关于KBQA方面的论文,这里只是简单的做个梳理,供后期查阅复习使用,并没有严格的复现等,参考了很多博客的论文笔记
—-开放领域的问答系统—-
Semantic Parsing on Freebase from Question-Answer Pairs
语义解析
Abstract
在Freebase上训练一个语义解析模型,因为标记问句中的逻辑形式对于一个大批量的问句来说太耗费了,这里使用语义解析来学习问题-答案对,这里主要的挑战是对于一个问题,如何缩小可能的逻辑谓词(这里就是KB中边的意思,比如问句中的出生地,一般问句中会提到bron,而我们需要将其对应到PeopleBornHere,这个PeopleBornHere就是KB中的边名)。我们解决这个问题使用两种方式,第一种方式是建立一个粗糙的对应关系,将短语对应到谓词上,第二种方式是使用bridging操作,即基于临边的谓词来产生中间的谓词(这里举了一个例子,比如Type.University和BarackObama之间可能存在什么谓词关系,这里就去遍历可能的结果,最后对应到Eduction,而这个Eduction就是bridging操作)
Setup
给定一个知识库K,一个问题-答案对,输出一个语义解析,该语义解析通过知识库K能够将新的问题x给出一个答案y,具体的定义形式如下:
定义了实体表示为e,谓词(边)表示为p
定义了三种操作:Join表示的是谓词与实体的结合,得到的结果是一个实体,比如谓词PlaceOfBirth和实体Seattle进行Join的结果是PlaceOfBirth.Seattle,其相当于一个实体eIntersection表示的是两个实体的交集,比如Profession.Scientist PlaceOfBirth.SeattleAggregation表示对实体进行统计,比如是一个实体,那么表示计算实体的基数
如上,也就是说对于每一个问句,先进行问句词的映射,然后再将这些映射使用上面的三种操作进行组合,最后会得到一个结果(查询语句),这里我们用d表示,如下图所示: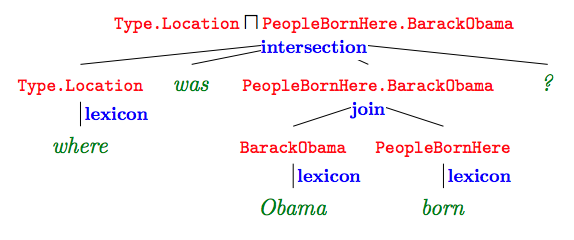
这里通过不同的操作组合就会得到很多d组成的集合D(x),我们用表示一个语义解析结果和中提取的特征向量,用表示对应特征的权重,这个是我们模型需要训练的.
定义给定问题后,语义解析为的概率为:
这里我们希望通过在K中查询的结果和正确的答案相同的对应的概率最大,使用对数似然函数,定义如下损失函数:
其中表示的是使用d语句在知识库中查询得到的结果,这里d的不同种解析组合方式可能对应相同的答案,这是第二个求和的原因。
Approach
做了两部分,第一部分是将自然语言短语映射到逻辑谓词上,第二部分是通过临边谓词生成连接临边谓词的逻辑谓词。(实体映射比较简单,这里的两部分都是谓词映射,即边映射)
关于第一部分的映射,比如自然语言短语born in是应该映射到DateOfBirth呢还是应该映射到PlaceLived.Location呢,这里需要考察自然语言短语两边的实体,比如对于三元组(“Obama”, “was also born in”, “August 1961”)的was also born in就应该映射到DateOfBirth,而(“Barack Obama”,"was also born in",“Honolulu”)的was also born in就应该映射到PlaceOfBirth,那么具体如何做呢?
这里使用ReVerbopen IE system的ClueWeb09(注:该数据集由卡耐基梅隆学校在09年构建,还有一个12年的版本,ClueWeb12)上抽取15millions个三元组构成一个数据集,先归一化,比如将(“Obama”, “was also born in”, “August 1961”)归一化为(BarackObama, “was also born in”, 1961-08),然后对于其中的自然语言短语,比如was also born in,统计其两边的实体类型,主语实体类型用表示,宾语实体类型用表示,用进一步表示,表示实体对集合。
同样的,对知识库中的实体关系两边的实体进行类似的统计,得到了实体集合,通过比较集合和集合的Jaccard距离(集合交集元素数目比集合并集元素个数)来确定是否建立自然语言短语和知识库边关系的映射,如下图所示: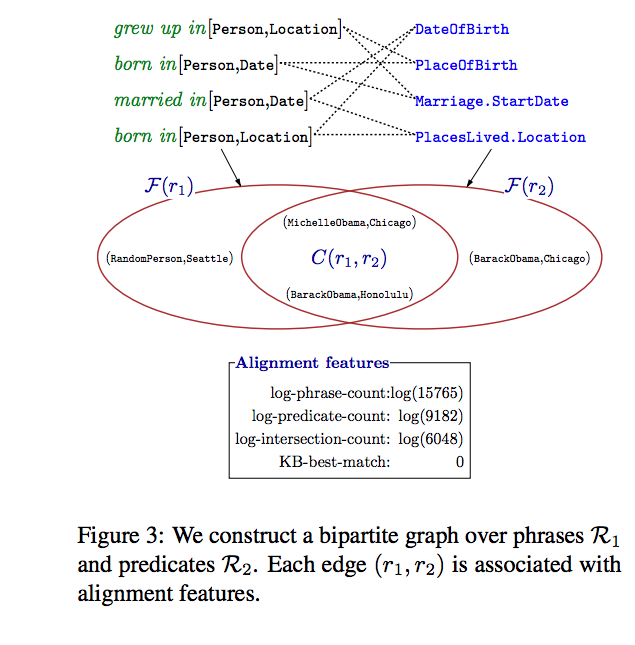
这里我用通俗的语言解释一下:比如对于自然语言短语was also born in,在给定的训练集中找出它全部的实体对,比如(“Barack Obama”,“Honolulu”),(“MichelleObama”,“Chicago”),对应的实体类型是(name,place),这样每一个自然语言短语都会生成一个集合,再到知识库中对实体关系(边)进行同样的操作,也会生成很多实体关系-集合对,那么对于自然语言短语was also born in对应的集合,遍历知识库对应的全部实体关系-集合对,使用类似Jaccard距离来判断两个集合的相似度,这里比较的是实体对的类型,也就是说图中交集部分的实体对类型全部相同,给定一个阈值,如果满足了,就将was also born in和知识库中的实体关系进行对应,如上图所示。
对应的词汇映射操作取如下特征(用来训练分类器,也就是前面提到的):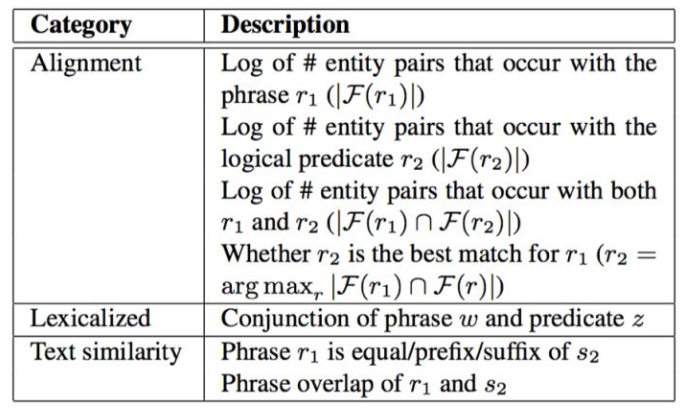
对齐特征:
- 自然语言短语对应的实体集合的大小的对数
- 逻辑谓词对应的实体集合的大小取对数
- 上面两个集合的交集大小取对数
- 是否是对应的最好的匹配
这里提一下第4个特征,前面提到会设置一个阈值,也就是说可能对应多个,肯定也会有一个排名,那么第4个特征的意思就是当前选取的映射是不是排名第一个。
词汇特征:
这个没看明白,短语w和谓词z的链接是什么意思啊???
文本相似度:
短语和知识库中的实体关系之间的文本相似度
桥接操作
具体来说,给定两个类型(type)分别为和的一元逻辑形式和,我们需要找到一个二元逻辑形式b,在b对应的实体对类型满足的条件下生成逻辑形式 ,这就是桥接,由于这里有类型的限制,所以我们可以在知识库中相邻的逻辑关系中暴力搜索符合条件的二元关系b
桥接的特征选取如下:
其它操作的特征如下:
这些特征含义论文中有讲到,没细看…
这样由上面的这些特征就会生成,而就是对应特征的权重,然后开始训练即可。
最后提到这种语义解析树的构建方式是指数级的,在训练和测试的时候,使用了beam search,什么意思呢,关于beam search我最早了解到的是在机器翻译这一块,比如我们训练好了一个翻译模型,那么对于翻译的句子,解码器对第i次输出,经过softmax后会有一个结果,一般就是取最大的对应的词作为第i次的输出,而使用beam search后,比如给定一个k,那么第i个输出的选取仍然是最大的对应的词,但是第i+1的输入会是第i次输出结果的前k个值分别作为第i+1的输入,也就是说每个值会有一个softmax,这里i+1的输出就会有k个softmax向量,选取最大的作为输出,选取前k个作为下一次的输入。
这里我的理解是:给定一个k,比如对于给定的一个句子,我们先进行映射,但是一个词可能有多个映射,我们只取前k个,那么这前k个映射后,后期的映射应该是每个都是k的扩张,最后的结果应该不可能只有k个。
Information Extraction over Structured Data: Question Answering with Freebase
信息抽取,相对于上一种语义解析提升超过了10%,这篇论文比上面的要好理解一些
Introduction
讲到KBQA被限制的原因:
- 知识资源
- 计算能力
- 稳健理解自然语言的能力
Approach
给出一个问题的一个和多个主题(这里的主题就是实体节点),在KB中找到对应的节点,通过对这个节点的几条进行分析,来提取结果。假设答案可以在KB中提取到,我们的目的是最大程度的获取到正确的答案。对于自然语言查询的一个挑战是:查询的不正式,比如who cheated on celebrity A,对于cheated on在数据库中的关系是不确定的。最好的解决办法是通过将一般的谓词(from ReVerb)映射到知识库中的关系上【这里的意思应该就是前一篇提到的通过关系两边的实体来实现关系的映射】
Background
KBQA面临两个主要的挑战:模型和数据,模型的挑战是发现最好的有意义的问题表示
Graph Features
比如what is the name of justin bieber brother,这里会找到实体justin biether,然后在对应的知识库中找实体的brother,但是实体只有sibling,那么如何解决呢?下面讲解其过程:
在回答上述查询的时候需要考虑多重限制,查找一个人的名字基于如下规则:
- 依赖关系
nsubj(what, name)和prep of(name, brother)表明问题寻找的是一个名字信息。 - 依赖关系
prep of(name,brother)表明名字是一个哥哥。(我们仍然不知道它是否是人名) - 依赖关系
nn(brother, bieber)和事实:Bieber是一个人名且人的哥哥也应该是人,表明名字是人名。
基于此做了如下的依存树修改:
- 问题词,用
qword表示,比如what/who/how many等 - 问题关注点,用
qfocus表示,是期望的答案类型,比如name/money/time,我们保持分析简单化,不适用问题分类,只是简单的提取qword和qfocus的名词依赖 - 问题动词,用
qverb表示,比如is/play/take等,从问题中提取主要的动词。问题动词对答案的类型来说是一个很好的暗示。比如,play
参考
1.Semantic Parsing on Freebase from Question-Answer Pairs
2.Information Extraction over Structured Data: Question Answering with Freebase
3.

