这里主要是结合论文来讲述,因为看Attention的时候涉及到了,就简单的介绍一下,后期有需求会继续更新
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
【14年发表的】这篇论文我只看了前半部分,讲到了RNN Encoder-Decoder和GRU,后面在做测试部分就没看了。
RNN
RNN模型是由一个影藏状态和可选的输出以及输入的可变序列,对于每一步,隐藏状态如下更新:
RNN 可以学习一个概率分布,通过预测一个被训练的句子来预测在句子中的下一个特征,每一步t的输出是一个条件分布,如下使用softmax函数:
其中表示在t步的输出可能的取值,有K种取值,对应着
如下图所示: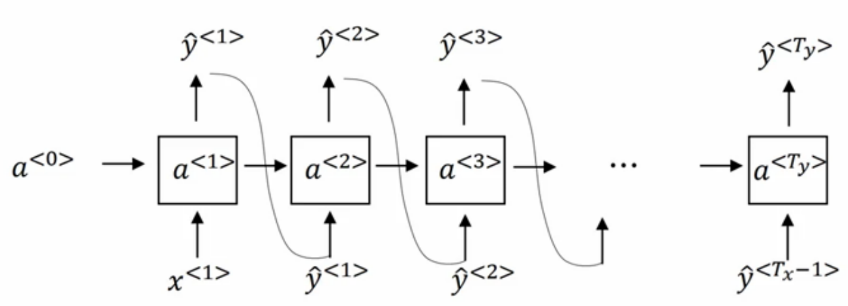
通过联合这些概率就能够计算出序列x的概率,如下:
RNN Encoder-Decoder
这篇文章中提出如下结构:通过学习编码一个可变长度的序列成一个固定长度的向量表示,解码一个给定的固定长度的向量成一个可变长度的序列。其条件概率如下:
其中不一定等于
模型如下图: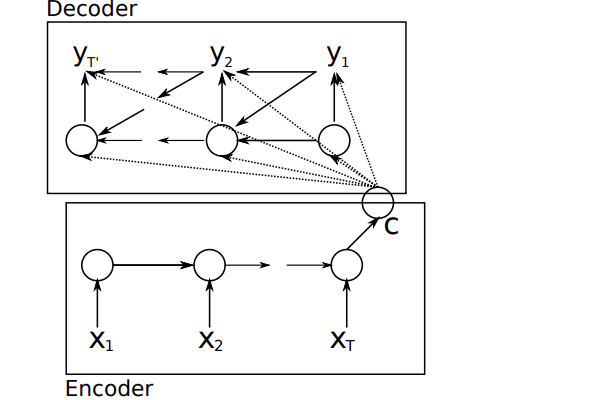
对于输出而言,其中隐藏状态如下:
而输出序列如下求解:
使用最大似然来估计参数:
这里的是训练集中的输入序列和输出序列,是训练集的大小
GRU
是对LSTM的简化,分为重置门和更新门
重置门如下计算:
更新门如下计算:
下一个隐藏单元如下计算:
如下图所示: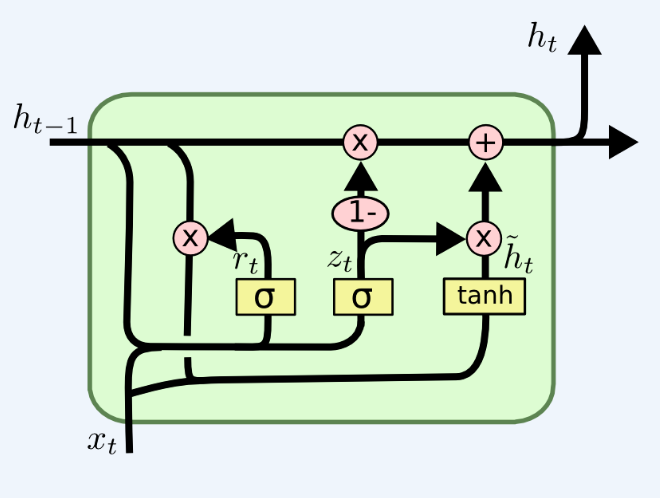
论文中做了如下解释(具体请参考原文):
如果重置门接近于0,则当前影藏状态就忽略了前面的隐藏状态,并将当前的输入作为当前的隐藏状态,这就允许隐藏状态去掉任何信息当发现这些信息在后面并不相关的时候,允许一个更加紧凑的表示。
更新门控制有多少的信息从之前的隐藏状态中带到当前的影藏状态中,这可以帮助RNN去记住更长的信息。
Sequence to Sequence Learning with Neural Networks
深度神经网络虽然已经在很多困难的学习任务上实现了一个很好的表现,但是仍然不能够使用在序列到序列的问题上,这篇论文提出了一种序列学习的通用端到端的方法,在这个结构上做了最少的假设。先使用一个多层的LSTM将输入序列映射到一个固定维度的向量,而另一个深度LSTM从这个固定的向量中解码出目标的序列,在英语到法语翻译任务中的WMT-14数据集中,test集得到了BLEU分数为34.8,将源语句序列进行逆转显著改善了LSTM的性能,因为这样会在源语句和目标语句之间引入很多短期依赖,从而优化问题更加容易。
基本模型如下图所示: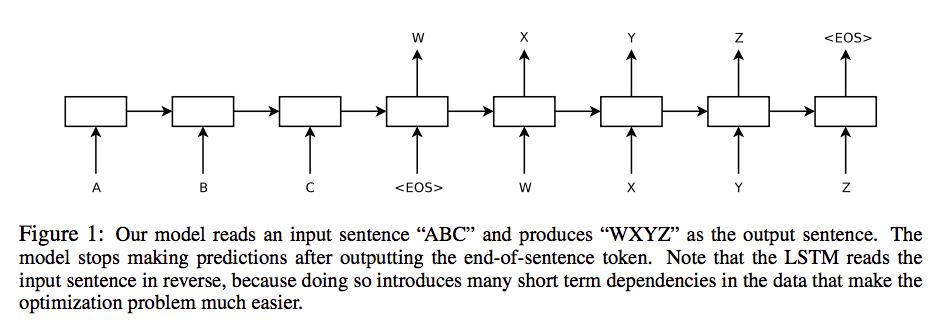
注意,前面提到的逆序输入,也就是说本来的输入序列是”CBA”,逆序后如上图所示,这样显著提升了LSTM的性能,对上面的句子我的理解是Encoder最后的输入是序列的第一个单词,而Decoder的第一个输出对应着翻译第一个单词的结果,离得比较近,依赖关系就比较紧,也就是说引入了很多短期依赖。
原始论文中Encoder和Decoder都是4层LSTM。
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
这篇文章对第一篇的结构做了如下改变:
- 将RNN改为BRNN
- 加入注意力机制,即c可变
其结构以及注意力机制的计算如下图所示:
注意力机制大概就是在说每次预测都是从向量c中进行信息提取,但是如果句子很长的话,c未必能把所有的信息都保留下来,而且比如对于输入句子”我/是/中国人”的目标语言是”I/am/Chinese”,翻译”Chinese”的时候显然取决于”中国人”而与”我/是”基本无关,上面加入注意力机制后,相当于对每一个进行权重求和,每一个输出所对应的上下文是不同的。
这里使用BRNN,相当于取当前词的上下文信息。

