主要学习资料是cs224n的notes和Michael Collins的notes,和宗成庆的《统计自然语言处理》,这里并不是一个完整的翻译笔记,而是在阅读的过程中对其中不懂的东西的一些解释,以及避免遗忘做的一些笔记,当然初入NLP,难免对一些知识理解不透或者有所偏差。
Context-Free Grammars
Noam Chomsky 曾经把语言定义为按照一定规律构成的句子和符号串的有限或无限集合,形式语言是用来精确描述语言及其结构的手段,形式语言学也称为代数语言学。
形式语法是一个四元组,其中:
- N是一个非终结符号(non-terminal symbols)的有限集合
- 是一个终结符号(terminal symbols)的有限集合
- R是一个规则集合,其形式如
- 作为一个句子的开始符或初始符
这里举一个最左边推导(left-most derivation)来理解上面的形式语法:
对于一个最左边推导的一串字符串,有如下:
- 是开始符
- ,是有终结符号组成的字符串(表示的是由中的单词组成的所有可能单词序列集合)【其实这里有个疑惑,最后的难道不就是句子本身吗,那么就只可能有一个啊,给个求和符是什么意思???】
- ()被从中派生出来,通过将中最左端的非终结符号X通过规则R中 替换
如下例子: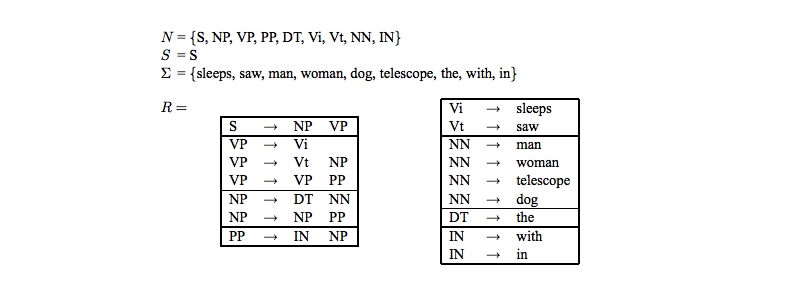
上面关于四元组的定义不懂的话,结合这个图应该能够看懂。非终止符就是S,NP,VP等这样的符号,比如NP代表名词性短语,等等;S=S只是一个句子的开始符标记;终止符就是具体的单词,比如sleeps,等等;而规则R表示的就是递进组合关系,比如VP可以由Vi组成,也可以由Vt和NP组成,等等。下面就是上面讲的序列,以句子the man sleeps为例:
- 其中为开始符,即
- 而就是在中找最左边的第一个非终止符,是S,在规则R中找到S可能对应的,即,这样
- ,由前面的中的NP在规则R中找,最为符合的就是DT NN
- ,由前面的中的DT在规则中找到对应的为the
- ,..
- ,..
- ,..
Ambiguity
这里和前面章节一样,讲到了句子通过形式语言来表示的话,会有歧义,比如句子the man saw the dog with the telescope用解析树(前面分析的串s可以被表示为parse tree)表示如下两种parse tree: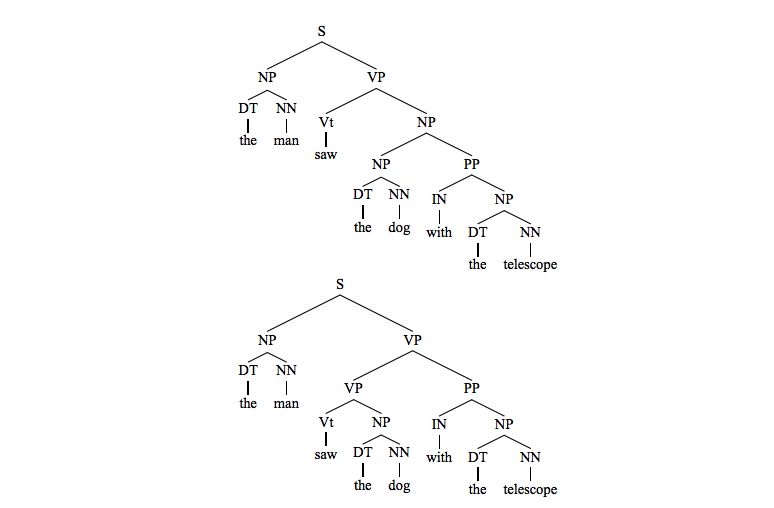
Probabilistic Context-Free Grammars(PCFGs)
下面就来计算一个句子用形式语法表示成的不同种parse tree的概率,选择概率最大的作为该句子的形式语法的表示,这里需要做一些说明。
记为在grammar G下的所有可能的parse tree,表示对于句子s的所有可能的parse tree集合,其中。
这里用表示对于任意的,生成该树的概率,这样有下面两个公式:
这样就将我们的问题转为如下式子:
此处讲义给出了三个问题:
- 如何定义函数p(t)?
- 如何学习p(t)模型的参数?
- 对于给定的句子s,如何求解最大似然树?
下面就围绕上面的三个问题来回答,这里就是我们要讲到的PCFGs,给出如下定义:
- A context-free grammar
- 参数 ,对于规则且任意,有如下约束:
那么p(t)的定义也就迎刃而解了:
在规则R中加入出现的概率,如下图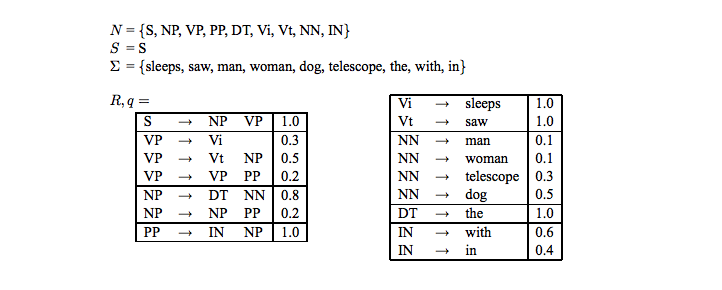
以句子the dog sleeps为例,下面解析树出现的概率如下: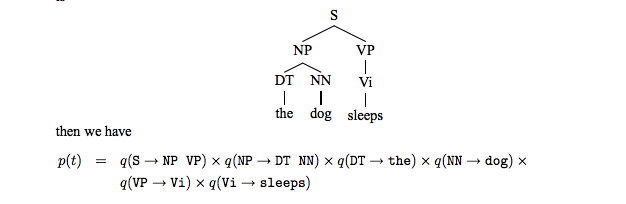
其中用最大似然估计:
参数表示在所有的解析树中,规则出现的次数,参数表示在所有的解析树中,出现的次数。
最后一个问题是如何求解 ? 用下面的算法
CKY algorithm
CKY算法是一个动态规划的算法,如下:
- 对于一个句子,对任意的,定义表示以X为根,句子
x_i...x_j的所有解析树的集合。 - 定义
我们最终要求解的式子就可以表示为
那么动态规划的初始条件如下:
通项公式:
最后用bp来记录规则和分隔符s,算法如下:
Inside Algorithm
这个算法我有点懵,不知道为什么要将这些可能的parse tree求和,而且求和的结果难道不是1吗???先放到这吧,后期明白了再补上。。。

