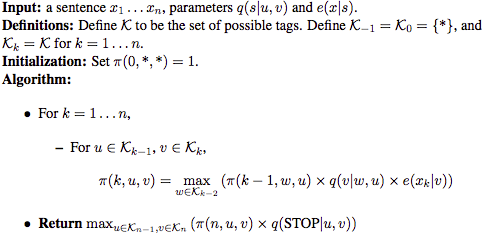主要学习资料是cs224n的notes和Michael Collins的notes,和宗成庆的统计自然语言处理,这里并不是一个完整的翻译笔记,而是在阅读的过程中对其中不懂的东西的一些解释,以及避免遗忘做的一些笔记,当然初入NLP,难免对一些知识理解不透或者有所偏差。
Introduction
对于一个句子,我们要做的是给每一个单词打上词性标记,比如句子the dog saw a cat对应的tag sequence是D N V D N,这个句子的长度是5,对应的输入,用来表示tagging model的output,对应上面的有。匹配句子的tag sequence 的问题叫做 sequence labeling problem 或者是 tagging problem。
Two Example Tagging Problems : POS Tagging and Named-Entity Recognition
前面讲到的就是POS Tagging,其有两大挑战,第一个是tagging的歧义问题,因为一个单词有可能是动词又有可能是名词;第二个是词库中的单词有限,导致训练例子中的单词可能在词库中没有出现,然后是Named-Entity Recognition,notes中提到的实体有PERSON,LOCATION,COMPANY。但是对这一块的讲解非常少,所以这里就不提了[后期如果有用会补上吧。]
Generative Models
这里主要是讲解隐马尔可夫模型应用在tagging问题上,这里以作为句子,作为对应的标签,我们的目的是在语料库集合中找到最符合句子的标签,即如下:
那么如何对于给定的,在Y中找到最优的呢,即如何求解p(y|x)呢,这里我们将上式转换一下,用贝叶斯公式求解:
由于对于x而言,求解全部y的概率,因此p(x)可以看成常数,也就是求下面的最大值对应的y:
Generative Tagging Models
对于单词集,标记集,定义为sequence/tag-sequence对,对于,,有如下要求:
那么对于给定的一个生成标记模型,从序列中标记出序列被定义如下:
这里就是找出全部的序列,其中,计算其中的概率值,将最大的概率值对应的序列作为模型的输出。那么如何计算这个概率呢,下面有讲到。
Trigram Hidden Markov Models
这里是Trigram,也就是说序列中只与和有关。
给出下面两个参数 :
参数 :对于任意的trigram(u,v,s),其中,其概率可由在看到s在bigram (u,v)后的概率。
参数 :对于任意 这个值可以表示为看见观测值x配对s的概率。
那么之前概率可以表示如下:
这里有。
那么为什么上面这个公式成立呢,这里是有一些假设的,这里使用随机变量序列和,其中n为序列的长度,假设可以取集合中的任意的值,可以取集合中任意一个标记,那么上式可以被定义为:
这里第一个连乘是没有问题的,但是第二个连乘是怎么得到的呢,下面一步步分析
这里先讲一下概率模型的求解,如下:
那么下面这个公式就知道怎么变来的了吧
这里做了一个假设,变量独立于之前的观测变量和状态变量 ,当被给出变量时。那么上面的式子就变为:
Estimating the Parameters of a Trigram HMM
这里定义一下为在语料库中标签s和单词x匹配的次数,那么上述的两个参数在语料库中的最大似然估计如下:
同样对于在语料库中为0的情况,我们用上一章中讲到的解决,对于为0的情况,也就是说在语料库中没有出现该单词,这里notes中给出一种解决办法就是使用伪词(pseudo-words)[这块没有细看,后期用到再补]
Decoding with HMMs: the Viterbi Algorithm
那么知道如何求解和,我们又知道
而我们的原始问题是发现一组使概率值最大的序列,即:
这里举个例子,对于输入的句子the dog barks ,假设标记集为,那么可能的标记序列可以是下面任意一种:
对于时,有27种可能,如果计算这种情况中的每一种,找出概率最大的那个序列,显然是不太现实的,我们需要用一种更为简化的方法来解决这个问题。
下面的维特比算法就给出这样一种解决办法,可以将时间复杂度由缩小到,使用的方法是动态规划,就是对一个长度为n的句子分解,给定初始条件,给出通项公式,即求长度为i的子句最大概率下对应的子标记和长度为i-1的子句最大概率下对应的子标记的关系,这样就可以求出长度为n的原句最大概率下对应的标记。
VITERBI ALGORITHM
输入的句子是,对任意的 ,任意的序列,且 ,定义如下函数:
这里举个例子如下:
继续,定义和,定义为序列 的集合,其中,定义:
给定初始条件:
给定通项公式:
算法如下: