此为TensorFlow框架官网学习笔记,原文为MNIST For ML Beginners
MNIST For ML Beginners
数据集
首先是下载数据集,如下:
MNIST数据集分为三部分,训练数据(mnist.train)有55000个,测试数据(mnist.test)有10000个,验证数据(mnist.validation)有5000个。关于这个,Ng的视频中讲到过,神经网络与深度学习的书中也提到过,验证集用来交叉验证来优化模型,测试集用于评估模型的表现。
softmax回归
这里输出层使用的是Softmax回归,简单的神经网络如下图所示,当让这里应该有784个特征(矩阵图平铺),输出层应该有10个神经元,这里输出使用独热编码,比如3用[0,0,0,1,0,0,0,0,0,0]表示。
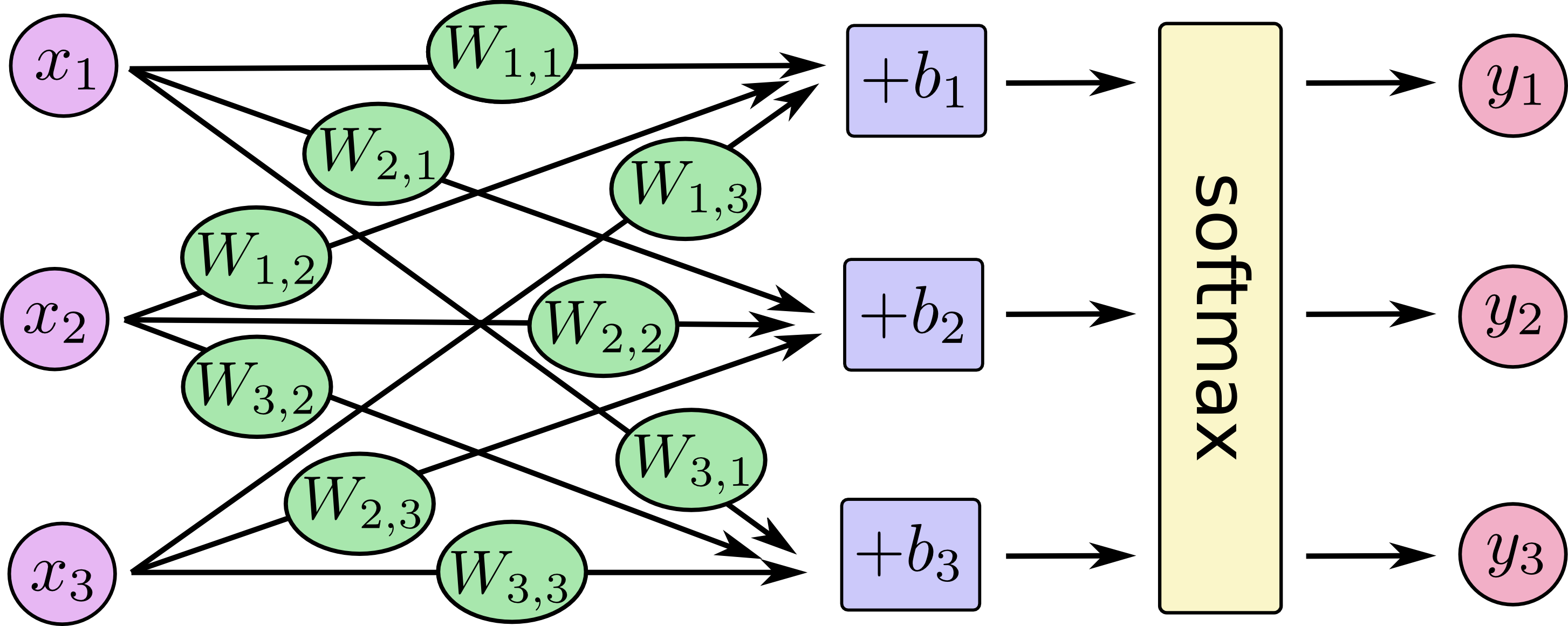
使用占位符创建输入变量,这里的行为batch的大小,使用None表示可以是任意长度,列为图片特征的大小:
|
|
W用正态分布来初始化(Ng的视频中提到为了防止梯度爆炸或者梯度消失,使用方差为1/n的正态分布来初始化),b用0来初始化,这里正规的W的行应该为当前层的神经元个数,列为上一层神经元的个数,这里写反了:
输出模型:
训练
损失函数使用的是交叉熵:
这里用y_表示真实标签集,使用占位符来接收一个输入,
交叉函数如下表示,其中reduction_indices=[1]表示对每一行求和,y_中每一列只有一个值是1,其他都为0,也就是说交叉熵的结果每一列只有一个值不为0,reduce_mean是求均值
关于这里用到的函数,给出理解的例子:
当然这里计算损失函数应该使用下面的函数,给出的原因是说上面的式子在数值上是不稳定的
然后是梯度下降,因为tensorflow知道计算的整个图标,会自动使用反向传播算法:
前面使用tf.Session()来创建会话,这里直接如下使用,表示默认会话,省去了注册默认会话的过程,不如第二行初始化,没有将其放在run中运行,而是直接使用run【纯个人理解。。。】
然后让训练运行1000次,这里每次batch为100:
模型评估
tf.argmax是一个非常有用的函数,它可以在沿某个轴在张量中输入最高的索引值,tf.argmax(y,1)将模型中概率值最大的索引输出,而tf.argmax(y_,1)为正确的标签对应的索引值,我们可以使用tf.equal来检查我们的预测是否符合事实。
输出为一个布尔的列表,这里我们需要转换一下,将布尔类型转为浮点数,然后取平均值,如[True, False, True, True]会变成[1,0,1,1],然后变成0.75,表示75%的正确率。
最后测试数据的准确性:
只有92%的正确率,当然我们都没有用隐藏层,完整代码见github
Deep MNIST for Experts
下面使用CNN来实现,这里就不介绍CNN的原理了,后面有时间会整理一下
Weight Initialization
这里避免梯度消失,使用ReLU激活函数,为了避免初始化导致神经元死亡可以将偏差设置为一个正数,这里将标准差设置为0.1,应该是为了防止初始化导致下一层Z过大,让该层所有的W之和的方差接近1.
Convolution and Pooling
这里提一下,卷积层中每一个节点的输入只是上一层神经网络的一小块,一般为3x3或者5x5,通过卷积层处理过的节点矩阵会变得更深,卷积层使用的过滤器会将上一层的过滤器大小的矩阵进行权重求和,得到的是一个值,深度为k时,得到k个值,这k个值是由于权重矩阵的权重不同而导致的,权重矩阵的深度就是卷积层的深度。池化层神经网络不会改变三维矩阵的深度,但可以缩小矩阵的大小。
strides表示的是不同维度上的步长,第1个和第4要求为1,因为卷积层的步长只对矩阵的长宽有效,padding表示填充的方法,SAME表示添加全0填充,VALID表示不添加全0填充。ksize表示的是过滤器的尺寸,第一个和第四个参数也必须是1,因为过滤器不能跨不同样本或深度。
First Convolutional Layer
第一层卷积层,其中对应的权重矩阵是一个5x5的过滤器,输入通道为1(由上一层决定),深度为32。
将x的维度变为4维的张量,第一维(batch)为-1表示先按照后面的维度,剩下的就是第一维的,第二维和第三维是图像的长宽,第四维是深度,如果是彩色图,那么深度就应该是3。
权重和经过卷积层后进入神经元,这里激活函数使用的是ReLU,从激活函数中出来,进入池化层,池化层步长使用的是2x2,也就是说最后的矩阵从28x28变为14x14。
Second Convolutional Layer
第二层卷积层中过滤器为5x5,深度为64,此时通过卷积层后,矩阵大小由14x14变为7x7。
Densely Connected Layer
这是全连接层,此时输入的矩阵长宽为7x7,深度是64,这里全连接层用1024个神经元,需要将三维矩阵转为一维作为输入:
Dropout
为了减少过拟合,在输出层之前用dropout,使用dropout可以在训练的时候打开dropout,测试的时候关闭dropout:
Readout Layer
最后,在全连接层上使用dropout,这里提一下,前面的h_fc1_drop根据keep_prob的值会随机的将h_fc1的某些结果置0。
Train and Evaluate the Model
最后一步训练然后评估,这里不使用梯度下降而使用ADAM,详细可参考Ng的深度学习视频,下面是训练与评估的代码:
每迭代100次后,就评估一次,最后使用测试数据评估,结果为99.2%,完整代码见github

