ABSTRACT
主题实体发现是去发现问题中的主要的实体,在问答中是明确的。传统的方法忽视实体的信息,尤其是实体的类型和它的层级结构,限制了其表现,为了去充分利用好KB并正确的发现主题实体,我们提出了一个深度神经网络模型去利用类型层次和KB中的实体关系。Experimental results demonstrate the effectiveness of the proposed method.
INTRODUCTION
KBQA的目标是去利用KB中简单的事实来回答问题,一般,KBQA系统有两个主要的部分组成:
(1)主题实体识别,问题中哪一个实体和KB中进行连接
(2)答案选择,哪一个定义KB关系和主题实体连接,选出正确的答案
之前的研究中鉴定实体通过存在的实体连接,比如Freebase API在问题中使用n-grams。为了更好的测量实体和问题上下文之间的相似度,一些统计特征被使用,但是,他们仅仅考虑字符串本身而忽略了问题的语义和KB中实体的信息,比如实体的类型和关系,这些在主题实体发现中是一个非常重要的信息,因为问题上下文的语义总是和主题实体的类型,关系很接近。比如,问题“Who is the CEO of Apple? ”表明实体“Apple”的关系是“CEO_of”,类型是“company”,所以主题实体是一个公司而不是食物,高效的关系已经被论证,使用KB关系去排序候选主题实体,并实现the state-of-the-art accuracy。但是会遭受zero-shot问题(就是训练集中出现,测试集中没有,牵扯到了one-shot learning),比如,测试实体的关系可能在训练数据中没有见过。这是由KB中巨大数量的关系造成的。比如在一个小型KB Freebase2M中就超过了6000个关系,Yu et al.将这些关系名称分解为4500个token,但是在test集中仍旧很容易发现未看到的token。众所周知,types constitute a multi-layered hierarchical structure,i.e., type hierarchy. 这可以自然的缓解zero-shot问题[It can naturally ease the zero-shot problem], 因为test 实体总有一个粗糙的父类,在充分训练后,罕见的子类可以得到支持从父类中。比如,Freebase中上千个类型可以被映射到112个分层类别上。
考虑分层类别不仅仅可以很好的理解问题的语义,而且可以避免zero-shot problem,我们提出Hierarchical Type constrained Topic Entity Detection (HTTED)取增加识别的正确率,它是一个神经模型取匹配问题和实体,通过学习问题上下文的表示,实体分层类型,实体关系。
THE HTTED MODEL
HTTED的关键想法是利用KB中的分层类型来建模子类和父类之间的相互关系,鉴于父类语义和子类语义的紧密相关性,我们表示父类由所有子类的语义组成:
其中tp ∈ Rd是父类型的嵌入,tci ∈ Rd是子类嵌入,d是一个嵌入的维度,⊕
是组合操作,在这个paper中,我们考虑额外的操作,比如向量求和,这些公式可以是模型共享参数在父类和子类之间,以至于帮助学习子类嵌入,避免受训练数据缺乏的影响。由于类型的分层结构,训练数据中父类要多于子类。
HTTED结构如下图,有三个模块组成:
(1) 问句上下文编码
(2) 实体类型编码
(3) 实体关系编码
给出一个问题q和它的候选主题实体Eq,HTTED学习问题上下文,实体类型,实体关系的表示,然后Eq根据在q和e∈ Eq的匹配分数重新排名[Eq是候选实体集合]
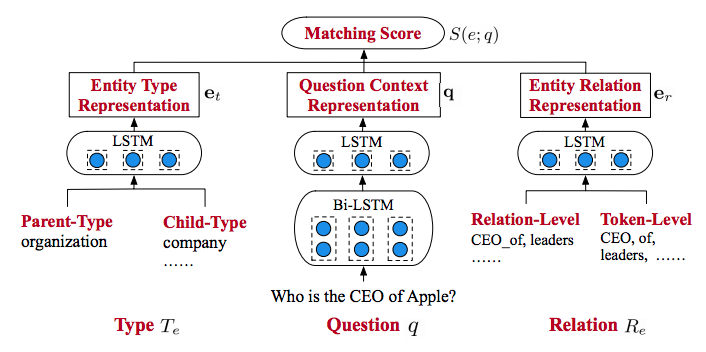
Question Context Encoder: 给定一个问题q,我们提取问题的上下文嵌入{w1,w2,…,wn}放到LSTM网络中,n是其长度,第一层是Bi-LSTM,将其输出放到第二层LSTM中,最后输出问题上下文表示q∈ Rd
Entity Type Encoder: For each e ∈ Eq, we get its linked types Te in KB.得到父类的嵌入,使用一个单层的LSTM在类型嵌入上去生成实体类别表示et ∈ Rd
Entity Relation Encoder: For each e ∈ Eq, we get its linked relations Re in KB. Additionally, relation names are broken into tokens RTe following [5], and the word embeddings of them are token-level relation representations. The two levels of relation representations are put into a LSTM network to get the last output as entity relation representation er ∈ Rd
Matching Score:
where α ∈ (0, 1). In training step, we maximize the margin between the positive topic entity e + and other negative ones e − with a ranking loss as following:
where γ is a constant parameter.

